随着2018年大规模预训练模型BERT席卷各项NLP任务成为最佳模型,2019年Joshi et al. 使用BERT代替原有词嵌入以及基于BiLSTM的上下文提取方法生成文本跨度的表征向量,并在基线数据集上的表现有了大幅度的提高。由于文本跨度表示在共指消解任务中的重要地位,Joshi于同年发布更适用于共指消解等跨度边界敏感任务的SpanBERT,该模型相比于原BERT模型达到了更好的效果。此外,来自清华大学的团队于2020年发布的以共指消解作为BERT模型训练任务的corefBERT也有着优异的表现。
0 基础概念
共指消解中的常用术语:
- 实体(Entity):现实世界中客观存在的可以相互区分的事物或对象,在共指消解中的共指簇;
- 文本跨度(Span):文本中任意长度的连续字符串;
- 表述(Mention):文本中指代某一实体的文本跨度;
示例如下:

1 BERT for Coreference Resolution: Baselines and Analysis
torch repo: https://github.com/cheniison/e2e-coref-pytorch
Joshi et, al. EMNLP 2019 同是UW与Facebook实验室的产出
随着大规模预训练模型BERT席卷nlp各项任务成为SOTA,Zettlemoyer团队开始尝试应用BERT模型完成共指消解任务。从结果上来看,在OntoNotes和GAP的基线数据集上的F1值分别提高了3.9和11.5. 本工作同时对比分析了BERT-base、BERT-large、ELMO模型效果的不同。
模型细节
模型基本延续原有模型框架,包括高阶推理以及Coarse-to-fine Inference筛选。其中不同的是,使用BERT模型代替原有基于Bi-LSTM的嵌入模型完成span嵌入。具体地,使用span中第一个word piece和最后一个word piece的输出向量以及span内部self-attention的和作为span的嵌入向量。
作者在论文中主要讨论了:BERT模型应用时的段分隔方式。在使用BERT模型进行嵌入时,由于最大输入长度为512个word pieces的限制,因此如何更好的分割文章成为作者的研究对象。
- 第一种分割方式是独立分割,即文章的每个分割段(segment)作为独立的实例被输入到BERT中。这将导致其中word piece的嵌入向量仅能感知到当前分割段内的信息,并且对于段边缘的词的表达效果并不理想。
- 第二种方式时重叠分割,顾名思义即每个分割段有一半的重叠,使得对段边缘的词拥有更好的表达。重叠的部分通过元素级插值的方式得到最终得嵌入表达。其中
是重叠部分不同的嵌入向量, 是可学习的参数矩阵。
模型评估
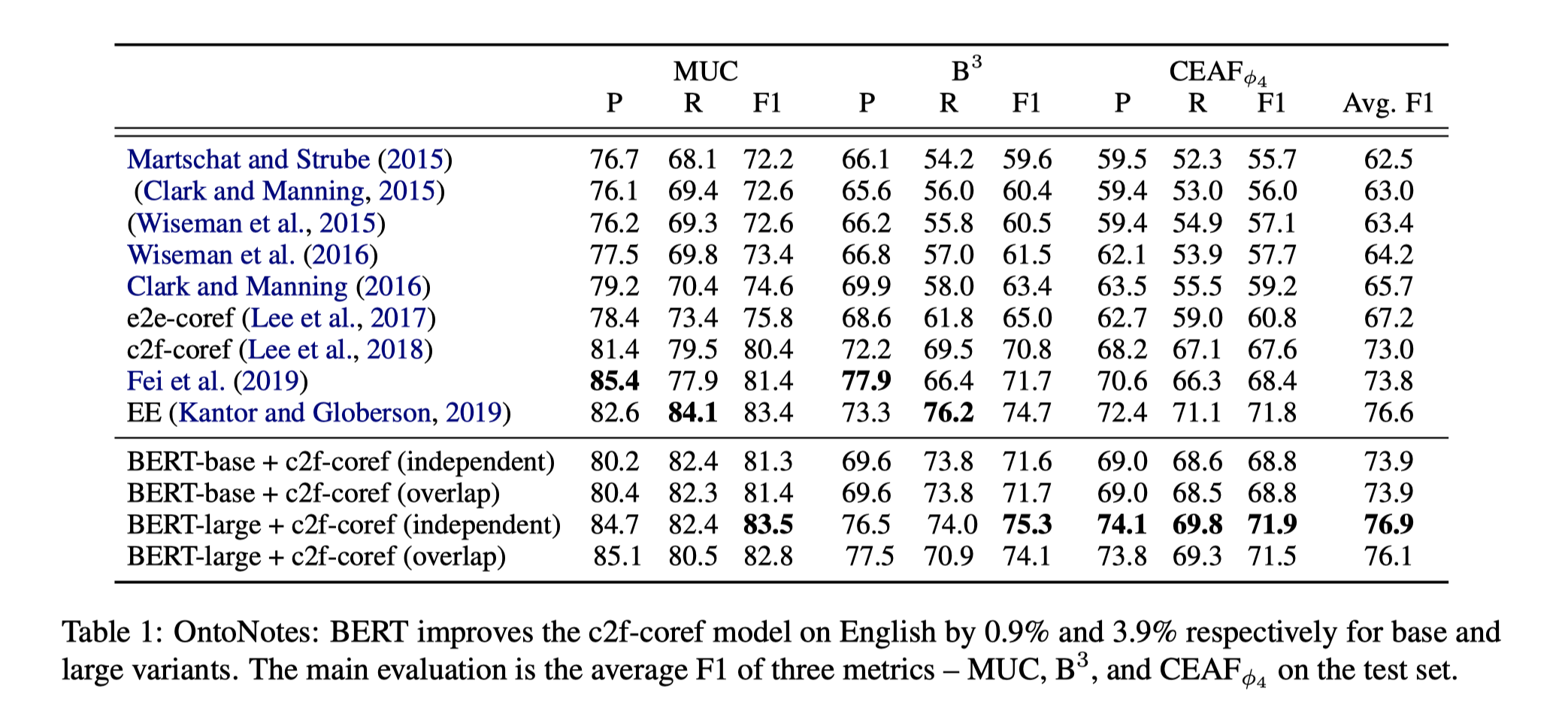
在OntoNotes(Document-Level)数据集上的结果:
在GAP(Paragraph-Level)数据集上的结果:
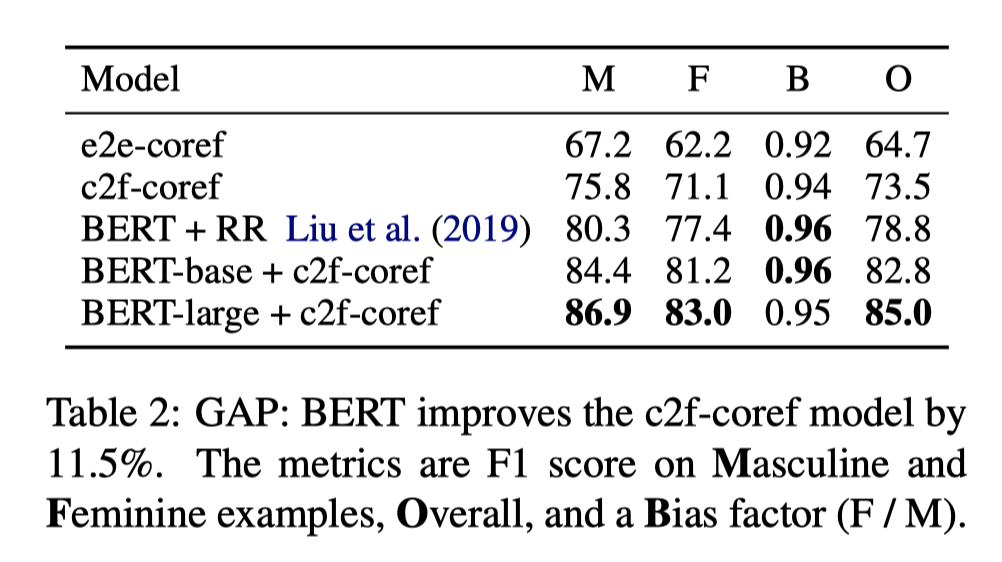
可以看到BERT-large+c2f-coref(independent)的模型表现是最好的。
结果分析
本文中作者通过错误分析(Error Analysis)以及超参数实验将模型优缺点(特点)展示的非常好,这种实验和写作方式十分值得学习。
Strengths
作者接着细致地对模型的预测进行了勘误,并对比BERT-large与BERT-base模型的区别。

由上图可以看到对于Related Entities(同义实体)和Lexical(语法相关)类型的共指推理,BERT-large模型表现的更出色,犯了更少的错误。在Pronouns(代词)类型的共指推理上,BERT-large模型表现稍好一些,而在Mention Paraphrasing(表述释义)、Conversation(对话)和Misc.(复杂情景)下,BERT-large模型与BERT-base模型都很难处理。
Weaknesses
通过以下实验,我们可以看到模型在处理长文章时表现欠佳。
由下图可以看出,文章越长模型的所预测的非正确类越多,犯的错误也越多。
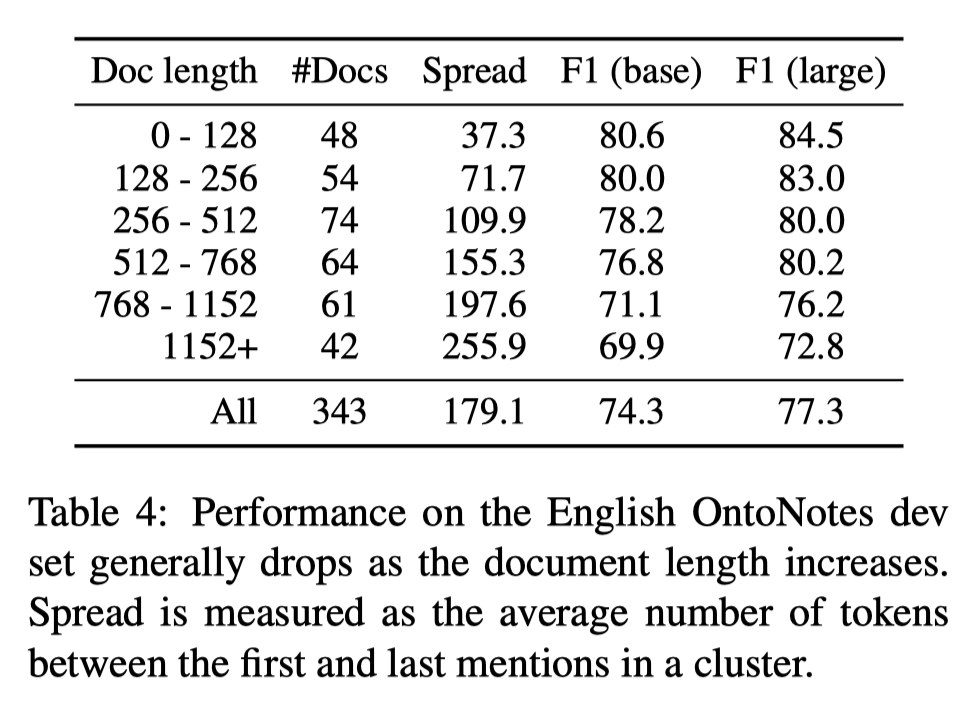
其次,更长的段长度并没有解决问题,反而段长度在450和512时,模型效果不如更短的段长度。作者给出的原因是BERT预训练时使用了更多的短序列,导致其在长序列上表现不佳。
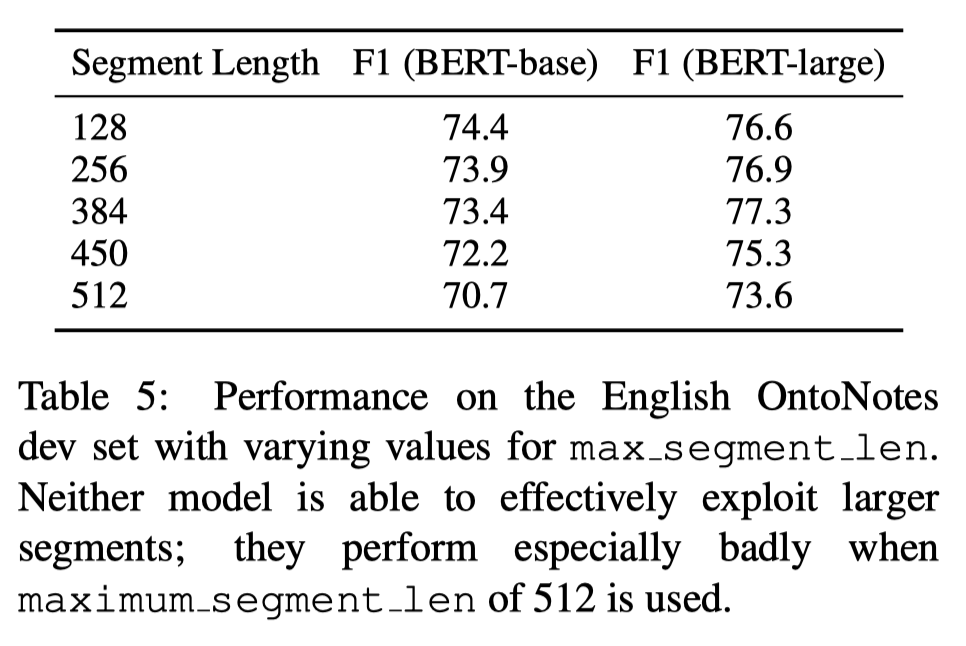
最后,我们看到使用重叠的分割方式并没有提高模型的表现。
所以这给我们的启示是我们需要更有效编码长序列的预训练模型来完成篇章级的共指消解问题。
2 SpanBERT: Improving Pre-training by Representing and Predicting Spans
Joshi et, al. TACL 2019 与上文同是UW与Facebook实验室的产出
SpanBERT是对BERT的从分词到文本跨度的优化,使其可以更好地预测文本跨度并表达文本跨度的含义。对于文本中的最小表义单元的表达,BERT分词级的遮罩预测的训练方式没有更好地体现文本中每个文本跨度的含义。作者提出了两种优化的BERT训练方式:1. 连续随机文本跨度的遮罩和预测;2. 通过文本跨度边缘前后的词语来预测该文本跨度的含义。在多项NLP任务基线数据集上进行实验发现,SpanBERT在文本问答、共指消解,、关系抽取等任务上的效果都要比BERT要更加出色。
SpanBERT自训练任务
作者的SpanBERT使用Span-Level的自训练方法,希望在下游Span Selection Task比如问答系统和共指消解任务上拥有更好的表现。与BERT的自训练任务不同的是,作者改进了遮罩任务的机制并引入了新的SBO(span-boundary objective)学习目标,最后取消了原BERT中的NSP预测任务。
Span Masking
文本跨度遮罩及预测任务(Masked Language Modeling,MLM)将从分词序列中总共选择15%进行遮罩。在每轮的选择中,首先采样文本跨度的长度。文本跨度的长度服从几何分布
的效果最佳),即 ,这样使得挑选的文本跨度长度偏向于较短的。此外,限制 的最大长度为10,所以可以得到平均的 应为3.8,即 . 在确定遮罩文本跨度的长度后,作者随机选择某个起始位置进行遮罩,但需要保证文本跨度的起始为是一个单词的开头并且被遮罩的文本跨度是完整的词而不是词的一部分子词。 在确定遮罩span的长度后,作者随机选择某个起始位置进行遮罩,但需要保证span的起始为是一个单词的开头并且被遮罩的span是完整的词而不是词的一部分tokens。
Span Boundary Objective
文本跨度边界预测任务(Span-Boundary Objective, SBO) 的目标是让文本跨度的边缘分词学习到文本跨度的内部信息。
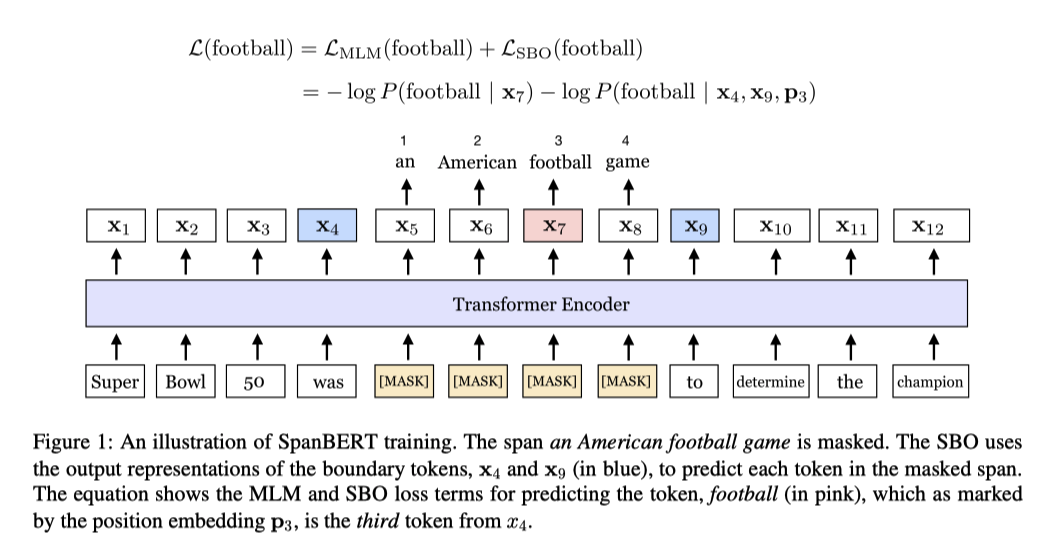
对于输入序列
,被遮罩的序列 ,我们希望通过span边缘的tokens的对应嵌入向量,即 和 ,加上位置嵌入向量得到表示span内部 的嵌入向量 ,使得 与由BERT输出的嵌入向量 足够相近。 其中, 为两层的前馈神经网络搭配GeLU激活函数和层归一化构成。 最后,
与 计算交叉熵作为Loss。SpanBERT的损失函数为MLM任务和SBO任务损失的和,如下所示:
模型评估
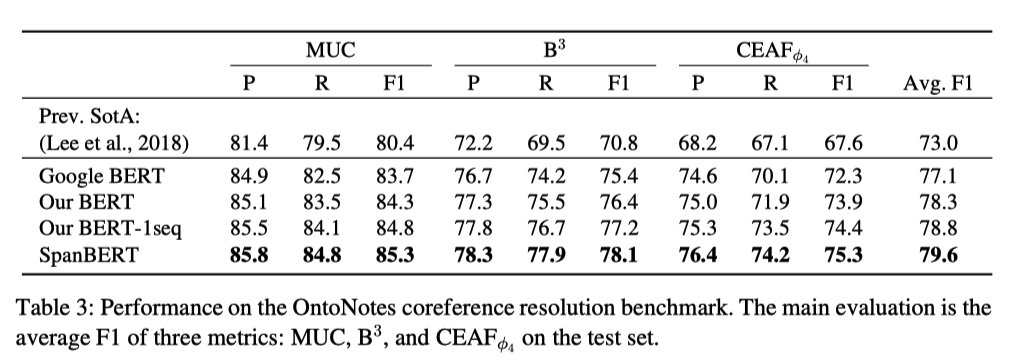
在共指消解任务上,SpanBERT的表现力压Google BERT和原BERT,拥有着最好的效果。
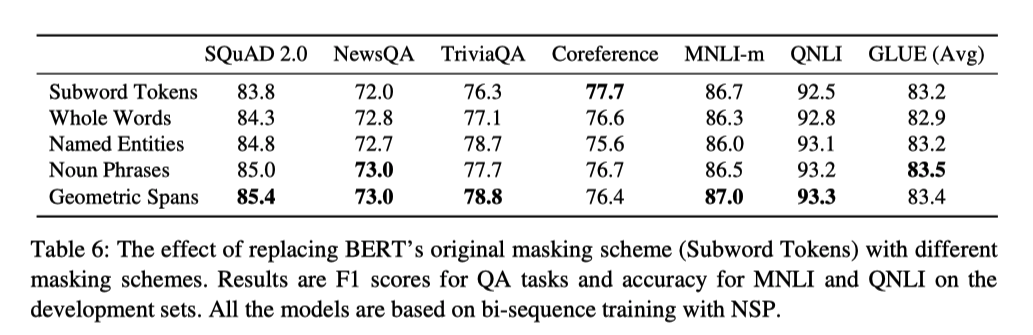
在消融实验中,作者还对比了不同的遮罩机制和不同辅助目标(NSP和SBO)训练下在下游任务上的效果。
对于不同遮罩机制,作者对比了随机Token级遮罩、整词遮罩、实体遮罩、名词短语遮罩、和Span中提出的几何分布遮罩。结果显示基于几何分布的遮罩效果是最优的。
对于辅助任务,SBO搭配Span级MLM有着最好的效果。并且再次印证了单序列输入要比两序列输入拥有更好的效果。
3 Coreferential Reasoning Learning for Language Representation
Ye et al., EMNLP 2020
Github: https://github.com/thunlp/CorefBERT
Paper: https://aclanthology.org/2020.emnlp-main.582.pdf
CorefBERT是清华大学团队发表的,继SpanBERT之后另一针对共指消解的BERT模型。由于共指消解任务对于文本理解、智能问答等其他NLP子任务起到至关重要的作用,Ye et al.直接地将共指消解任务作为BERT模型的自训练任务,并与SpanBERT相似地在多个NLP子任务上进行实验,达到了比较好的效果。
作者创新地提出了表述指代预测任务(Mention Reference Prediction, MRP)并搭配原有的遮罩预测任务(Masked Language Modeling, MLM)完成了CorefBERT的训练。接下来对MRP任务进行详细地阐述。
MRP任务的目标是学习到文本中表述共指的信息,在假设文本中重复的名词或者名词短语共指的假设前提下,对文本中重复出现的名词或名词短语作为表述进行遮罩,并试图用上下文信息来对其进行预测。具体地,作者首先使用POS词性分析器将文本中所有的名词进行标注,接着,将完全相同的表述划分至相同的共指簇中。每次选取一个共指簇中的一个表述进行遮罩。对于遮罩表述的预测,作者采用基于复制的目标函数(Copy-based Training Objective),使模型可以正确预测文本中的与遮罩相同的分词部分。对于输入序列