除了第一、二阶段中所提出的经典结构之外,有许多其他的工作对于共指消解问题中面临的解决框架、长文档、计算效率和内存空间等关键问题进行了探索。
由于前两个阶段中工作的连续型较强,而本阶段工作比较发散,因此在本章书写时我尽量给予它们分类的标题。
0 基础概念
共指消解中的常用术语:
- 实体(Entity):现实世界中客观存在的可以相互区分的事物或对象,在共指消解中的共指簇;
- 文本跨度(Span):文本中任意长度的连续字符串;
- 表述(Mention):文本中指代某一实体的文本跨度;
示例如下:

1 基于词层级的共指消解
词层级的共指消解模型于2021年被Kirstain et al.创新地提出,并在基线数据集上达到了与基于文本跨度的共指消解模型相近的效果。Dobrovolskii继承了Kirstain et al. [66]希望从分词层级而不是文本跨度层级完成指代消解任务的思想,在基线数据集上的效果超越了基于文本跨度的最佳模型效果。词层级的共指消解是很有创新性的。因为一直以来,先提取文本跨度作为候选表述,然后对候选表述进行消解是解决该任务更直接的想法,而基于词层级的方法反其道而行之,首先从词的层面完成指代消解,然后再从词生成其对应的表述,将共指关系由词对应到候选表述。
1.1 Coreference Resolution without Span Representations
Kirstain et al., ACL IJCNLP 2021
torch repo Github: https://github.com/yuvalkirstain/s2e-coref
Paper: https://aclanthology.org/2021.acl-short.3.pdf
1.2 Word-Level Coreference Resolution
Vladimir Dobrovolskii, ACL EMNLP 2021
Github: https://github.com/vdobrovolskii/wl-coref
Paper: https://arxiv.org/pdf/2109.04127.pdf
本篇论文继承了Kirstain et al的思想,希望从词的层面而不是文本跨度的层面完成指代消解任务。
Word-Level的方法有两点好处:1. 减少计算的复杂度,从
Word representation 词向量表达
Stage Two中论文主要在研究如何从subtoken/token得到更好的Mention表达,而基于Word-Level的方法只需要考虑如何从subtoken生成Word的表达即可。原文中使用的是token和suntoken其实就是word以及由BERT分词生成的subtoken。本论文中的计算方法是将subtoken的词嵌入按照权重求和得到word的嵌入表达。对于subtokens的嵌入矩阵
,我们可以简单的计算得到其对应的权重 ,最终对应相乘再求和得到该word的嵌入 . Word-Level coreference resolution 词层级的指代消解
本文中仍采用由粗到细的筛选方式,首先由简单的共指评分函数
对所有wordpair进行评分,对于每个word选择评分最高的K个候选先行词,接着引入更加精细的共指评分函数 对每个word从K个候选先行词中选择得分最高且大于0的作为预测的先行词,建立共指关系。 Span extraction 表述(文本跨度)提取
现在我们拥有了词的共指关系,本部分需要解决的问题是如何将词对应到表述Mention。首先我们需要明确一个概念:关键词/中心词(headword)。每一个表述都可以对应一个关键词,表述的关键词是通过句法依存分析得到的唯一依赖于该表述之外的词语或者整个句子的root,或者启发式的最正确的那个词语(通常为表述的最后一个词)。通过关键词的概念,我们可以将表述或者Span对应到词,也可能根据词生成表述或者Span。具体的方法介绍如下:
我们首先假设一句话中的每个词都是关键词或者中心词。遍历每个词,使用带有卷积核的前馈神经网络对此句话进行打分,得到以该词作为关键词的条件下,每个词作为span开始和span结尾的可能性评分。本质上来说,就是对句子的每个词完成是否为span起始和是否为span结束的二分类任务(TODO: 多分类)。最佳的Span边界就在于最可能属于该span的token和不太可能属于该span的token之间。当然还有其他的限定条件如span的开始需要小于等于关键词的位置,span的结束需要大于等于关键词的位置。基于此方法,我们就可以得到每个word对应的span,将word的共指关系对应到span即可得到Mention层级的共指消解簇。
模型训练
为了训练此模型,我们需要根据以mention作为单位标注共指的数据集生成以word为单位标注共指的训练集。具体的生成方式是借助于Stanford NLP tool对语句完成句法分析,提取mention中唯一的依赖于此mention以外的词语作为关键词。如果有多个词依赖该mention以外的词语则根据启发式的思想直接提取Mention的最后一个词。
模型的损失函数包括以下两个部分:
用于完成共指消解任务, 用于完成span提取任务(本质上是对句子的每个词完成是否为span起始和是否为span结束的二分类任务)。
2 借鉴文本问答思路的共指消解
2.1 CorefQA: Coreference Resolution as Query-based Span Prediction
Wu et al. 2020 ACL
Paper: https://aclanthology.org/2020.acl-main.622/
torch repo: https://github.com/YuxianMeng/CorefQA-pytorch
3 有关内存空间
3.1 Incremental Neural Coreference Resolution in Constant Memory
Xia et al., EMNLP 2020
Paper: https://aclanthology.org/2020.emnlp-main.695.pdf
Code: https://nlp.jhu.edu/incremental-coref/
4 讨论高阶推理
4.1 Revealing the Myth of Higher-Order Inference in Coreference Resolution
Xu et al., ACL EMNLP 2020
Github:https://github.com/emorynlp/coref-hoi
Paper: https://aclanthology.org/2020.emnlp-main.686.pdf
高阶推理算法已成为目前完成指代消解任务方法的标配,使得对span的表达引入全局的共指信息。本文对目前用于共指消解任务的高阶推理算法进行探究其必要性。作者实现了四种高阶推理(higher-order inference)算法包括attended antecedent, entity equalization, span clustering和cluster merging,其中后两种为作者自己提出的。作者使用SpanBERT作为编码器,以CoNLL 2012作为数据集探究不同HOI算法对结果的影响。
论文主要研究内容
作者采用的论文1.3和1.4提出的基于BERT(SpanBERT)嵌入的共指消解模型,因为这种方案是公认的共指消解任务的SOTA解决方案。接着作者介绍4种Span表示的优化方案,这些优化方案的目的就是在span本身内容和context的基础上为span表达加入更多全局(同一共指簇其他span)的特征。
方案1和方案2的更新span嵌入向量的方式都可以用以下门控机制公式来表达,只不过其中优化span嵌入向量
的获取是不同的。 Attended Antecedent (AA)
此方案为论文1.2中提出的,通过先有先行词分布来
来计算 ,详情可以参考之前的文章。 Entity Equalization (EE)
此方案参考了论文Ben Kantor and Amir Globerson. 2019中提出的方案,其中心思想也是显式地将属于同一共指簇的span的嵌入向量相加再取平均。但是由于该过程是不可微的,作者又借鉴了Le and Titov, 2017的论文来将此过程可微化。
但是由于该方案的效果并没有很理想,在论文中仅仅比方案1提高了0.3%左右,所以具体细节有时间再研究。
Span Clustering (SC)
SC其实是方案二不可微的原始版本,并且也没有采用门控机制来更新嵌入向量。在此方案中,作者没有此采用“软”的实体共指聚类过程,而是采用模型预测阶段的方法获取当前状态下的所有真实的共指簇。比如对于
,我们可以获取当前状态下的共指簇 ,接着对簇内所有span使用attention来获取当前 的嵌入向量。
5 迁移学习
5.1 Probing the SpanBERT Architecture to interpret Scientific Domain Adaptation Challenges for Coreference Resolution
Timmapathini et al., AAAI 2021
Paper: http://ceur-ws.org/Vol-2831/paper10.pdf
随着2020年的SpanBERT成为CR任务的SOTA模型,本工作分析研究了SpanBERT在专业领域文章上CR任务的表现。作者使用SciERC数据集进行实验,该数据集包含了500篇科学领域论文的概述,具有科学领域文章常见的句法、表达方式以及专业领域术语。通过在该数据集上进行实验,作者对SpanBERT的编码器和Coarse-to-fine先行词筛选机制进行探究分析。
实验一:对于SpanBERT编码器的探究
出色的span边界确定
在SBO目标任务的训练下,SpanBERT对于Span边界的感知非常优秀,大多数候选的top spans都拥有着正确的边界。
挣扎的语义表达
作者为探究编码器对于span的语义表达,采取的方案是查看其中每一层Transformer中attention机制能否捕捉到span与span的相似性或关联性。可以预见的是,如果attention机制具有出色的语义表达能力的话,使用具有关联的Spans分别做Query和Key得到的注意力分数应该是较高的。依据此思想,作者完成了以下实验。
由于作者对于此实验的表述不够详细,所以部分内容为我对其实验过程的揣测并使用更为易懂的方式进行表达,旨在表达其实验的核心思想。如有错误还请指正和见谅。
对于文档
, 我们首先可以得到其中所有手动标注的表述spans集合 。接着,通过 函数的挑选,我们可以得到候选表述span列表,对于属于该列表的任意 我们可以通过由粗到细的筛选工作得到得分最高的K个候选先行词集合 。最终,我们可以得到模型输出的共指簇集合 (包含 )。 SpanBERT中的注意力机制为多头的自注意力机制,但这并不妨碍我们使用其训练好的参数矩阵
和 来计算不同span间的注意力得分。对于 和 ,不妨假设其嵌入后的向量分别为 和 ,其中 , 。接着,我们可以得到Query矩阵和Key矩阵以及由点积缩放得到的注意力评分。 多头的注意力机制可以理解为对于X、Y的拆分,并分别完成以上计算,故本质上并无差别。
对于集合
内的span,可以理解为是实体表述且与 属于同一共指簇。若对于此集合内部的span捉对计算注意力评分,该注意力评分理应较高。对于集合 内的span,可以理解为是实体表述但是不与 同属于一共指簇。那么如果分别从集合 和集合 各取一span组成span对,其注意力评分理应较低。但是实验结果并不如愿,两者的注意力热度图没有明显的区别而且注意力得分都非常低。 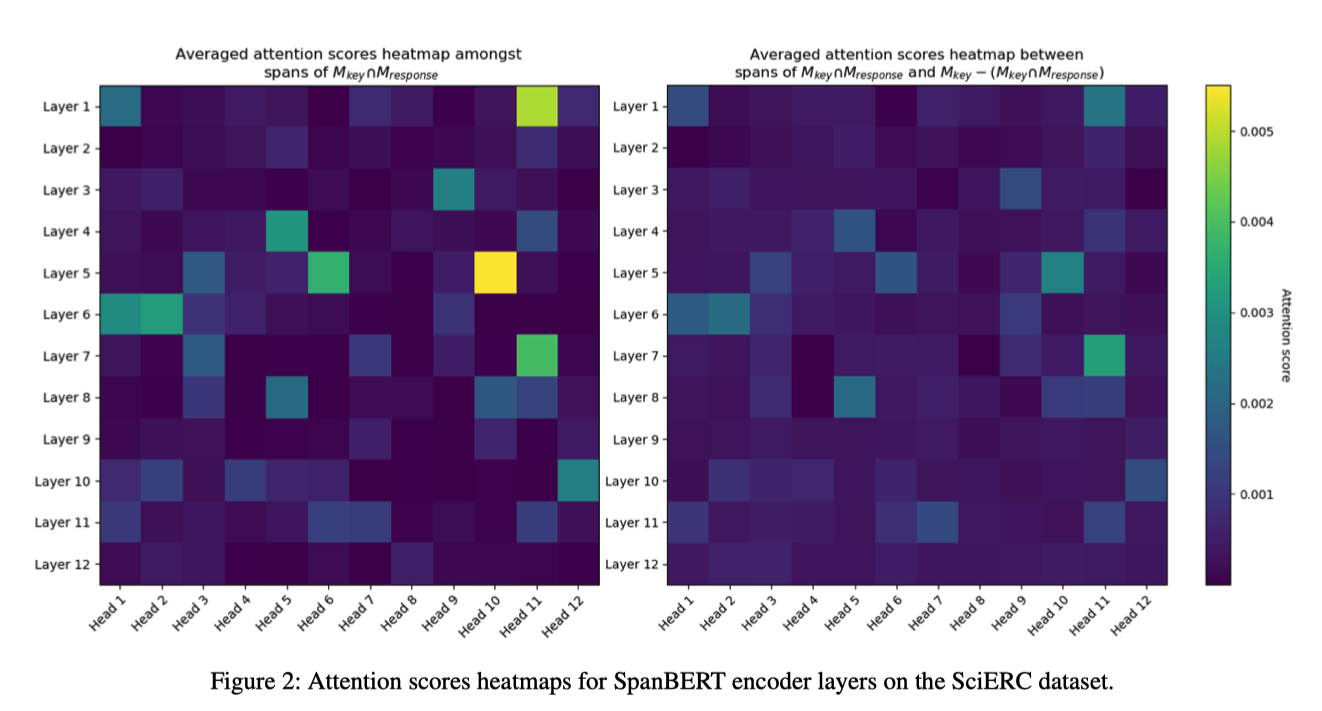
所以,作者根据以上热度图得出结论:1. 编码器对于span的语义表达是较差的;2.SpanBERT中各层和每层中注意力机制的头没有明显的用于表现共指任务的作用;
最后需要说明的是,作者并不是对每个span_i都做了一遍实验,而是在一开始时对候选表述span列表中所有span所生成的候选先行词集合和共指簇集合分别取并集,即可得到全局的候选先行词集合
和 . 理应来说,全局的 和 在实验中会有叠加效应,但是也并没体现出来。
实验二:对于Coarse-to-fine筛选机制的探究
作者接着对Coarse-to-fine的筛选机制进行探究。SpanBERT使用coarse-to-fine筛选完成指代消解任务的流程如下:
- 对于文章D中所有的span,通过表述Span函数
筛选得到top M个span作为表述集合。其中 - 对于每个筛选的表述span,通过表述对评分
从表述集合中得到K个候选先行词。其中 - 对于这K个候选的先行词,使用更加精细的表述对评分函数
得到得分最高的先行词。如果得分最高的先行词仍为负数,则该表述span的先行词为空。
如果我们希望span共指消解的效果足够好,那么步骤1中筛选的表述集合应该尽可能多地和真实的表述集合重叠。文章中
为第二阶段后所有筛选得到的表述集合,包含每个表述集合及其对应的候选先行词。作者对超参数 进行实验,发现统计数据如下所示: 
集合的元素个数由于 的增大进行了翻倍,并且 的值也按比例升高了,说明 的增大确实引入了更多正确的表述span。但是,观察 的值我们发现,更多的候选表述和候选先行词并没有使模型预测出来更多的含有共指关系的span(共指关系)。并且,从预测的共指簇的span中正确的数量来看,与标注的共指簇中的span相比,P、R、F1值都显得非常可怜。 最后,从共指的评价指标角度来看,模型的效果同样是非常的惨不忍睹。 毕竟预测正确的span都少的可怜,再加上正确共指簇的预测,效果肯定更差。
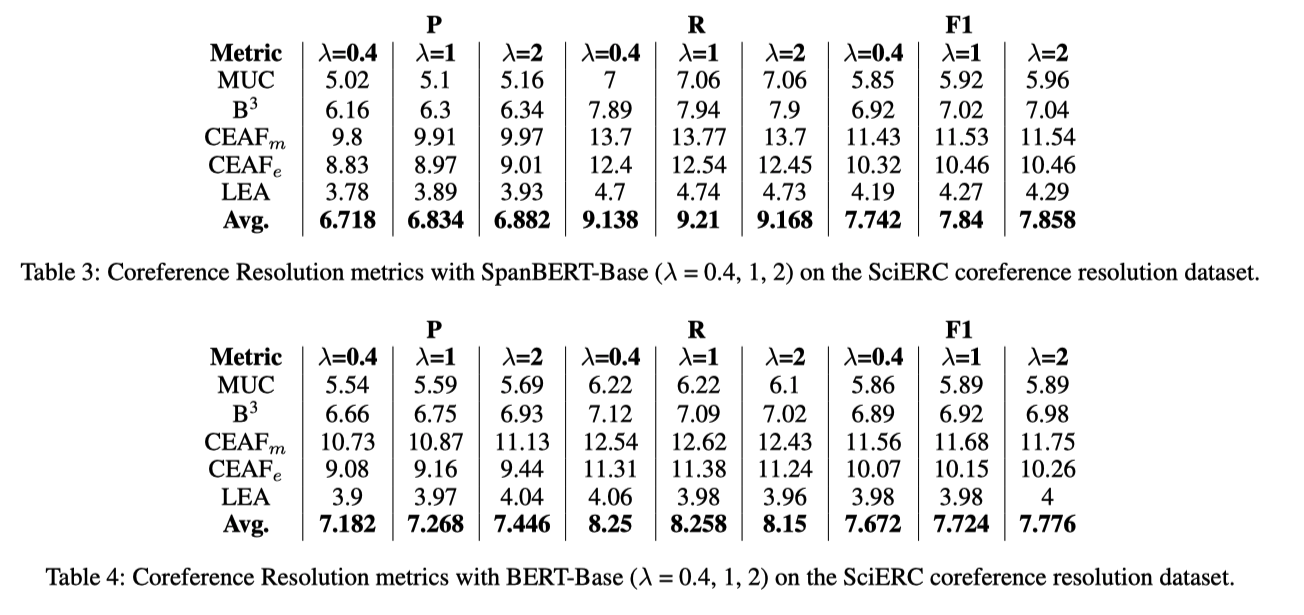
最终,作者将此结果归因于SpanBERT对专业领域术语赢弱的表达能力。
- 对于文章D中所有的span,通过表述Span函数
改进意见
- BERT基于Word-Piece的分词方式对于OOV(Out-of-Vocabulary)词语的表达能力很弱,所以我们应该尝试基于频率(frequency或者likelihood)的分词方式如BPE-Dropout、SentencePiece来拥有更好的sub-word选择。
- 当拥有足够大的数据进行微调的时候,需要对fine-tuning技术进行关注以避免对之前大量数据所得到的许多关键信息的遗忘。
5.2 Coreference Resolution in Research Papers from Multiple Domains
Brack et al., ECIR 2021
Paper: https://link.springer.com/chapter/10.1007/978-3-030-72113-8_6?noAccess=true
5.3 Moving on from OntoNotes: Coreference Resolution Model Transfer
Xia et al. EMNLP 2021
torch repo: https://github.com/pitrack/incremental-coref