基于神经网络的实体共指消解相关论文解读
- Published on
简介:
本文介绍了基于神经网络的实体共指消解的4篇基石文章,均为UW实验室的产出。四篇文章一脉相承,不断改进,对基于神经网络的共指消解解决方案有着指导意义。
首先把这四篇论文放在这里:
- End-to-end Neural Coreference Resolution
- Higher-order Coreference Resolution with Coarse-to-fine Inference
- BERT for Coreference Resolution: Baselines and Analysis
- SpanBERT: Improving Pre-training by Representing and Predicting Spans
1 End-to-end Neural Coreference Resolution
Lee et al., EMNLP 2017
端到端模型开篇之作,抛弃了基于语义或者手工特征的传统模型。采用span-ranking模型解决共指消解问题。
1.1 问题建模
该模型对于文档级共指消解问题提出span-ranking架构,建模为span对评分问题。首先将长度为T的文档分为T(T+1)/2个span并排序,对于每个span,从该span之前的所有span中通过评分函数挑选其最佳的先行词。
1.2 模型细节
Span对的共指评分函数如下:
其中函数用于评价该span是否为实体表述,函数用于评价两个span是否存在共指关系如下所示:
每个span的嵌入向量包括两部分:使用Bi-LSTM提取的span所在句的context信息;使用Attention提取的Span内部的关键词信息;如下图所示。
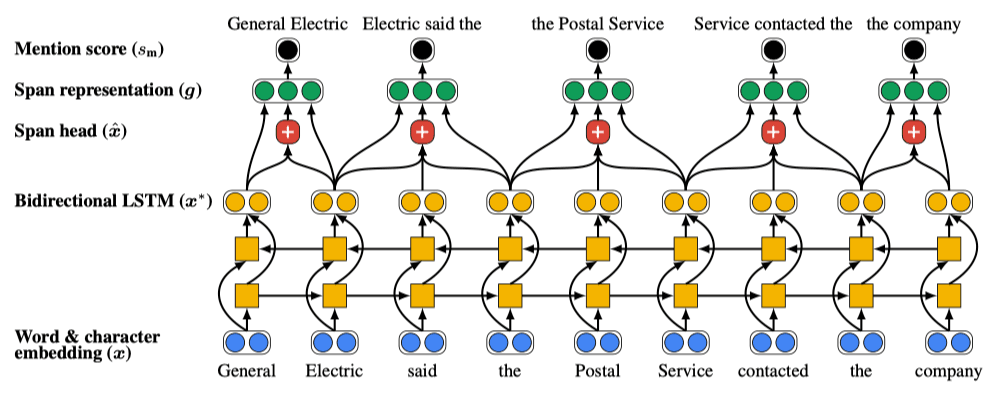
1.3 模型训练
对于Baseline Model,我们的训练过程如下所示:
首先根据函数所有span进行挑选,得到序列
接着通过嵌入函数为所有挑选出来的span进行嵌入,得到
计算目标函数
最大化目标函数,反向传播更新模型参数,重复步骤1,2,3,4
如何解决算法搜索空间过大,复杂度过高的问题:
首先规定Span长度的上限为L;通过函数对所有span进行评分,只选取得分最好的部分span用于候选。对于每个Span,仅选取K个潜在候选的先行词。
1.4 Strengths
模型具有可解释性,采用head-finding attention机制来显式地表示片段中对共指决策帮助最大的分词
1.5 Weaknesses
深度学习模型的优势是通过Embedding可以准确找到词语间的相似度,但是这也将导致过多的假阳性案例。比如案例3和案例4中的flight attendants 和 the pilots, Prince Charles Camilla 和Charles and Diana. 模型一旦过度依赖(overuse)词语间的相似性将导致这种情况的频繁发生。

模型没有引入world knowledge(common-sense reasoning)。
2 Higher-order Coreference Resolution with Coarse-to-fine Inference
Lee et al., NAACL 2018 与1同是UW的实验室的产出
2在1的基础上在两点上进行了改进:使用先行词分布做为注意力权重迭代更新Span的嵌入向量;提出了由粗到细的剪枝方法极大地提升了计算效率。
2.1 问题建模
2.对于共指消解任务的建模与1.相同,仍是延续了span-ranking的架构。
2.2 改进细节
高阶共指消解(Higher-order Coreference Resolution)
我们可以看到span对共指与否的判断非常依赖span的嵌入向量,而1.中span的嵌入没有考虑到如果其已经被划分入共指簇后,整个共指簇的信息。所以作者在每个span的嵌入向量上加入了已划分的先行词的影响,以更好地帮助模型学习同一共指簇的特性。
本文中,作者对上述过程进行了优化,对步骤2.进行了修改,如下所示:
2-0 初始情况下,t=1
2-1 根据原步骤2得到序列
2-2 计算得到当前轮次 下的
2-3 根据当前参数,我们将每个span的先行词的先行词分布(先行词的共指簇)作为注意力权重,可以得到每个span的先行词的嵌入向量
2-4 使用门控机制融合当前轮次下span的嵌入向量以及span对应先行词的嵌入向量得到下一轮次span的嵌入向量。
2-5 置 t = t+1 重复步骤2-1, 2-2, 2-3, 2-4, 2-5 直到 t > T (预先设定的轮次,实验中T=2)
由粗到细的推理(Coarse-to-fine Inference)
Baseline模型中,在推理环节为节省计算效率,对于每个span只考虑最邻近的K个span作为候选先行词。但这人为地限定了共指关系的最大距离,而导致模型预测效果受限。但是当使用共指评分函数作为筛选时,又大幅地增加了计算成本。
在本文中,作者提出了以损失一定准确率为代价但计算效率更高的共指评分函数来代替原有计算成本更高的共指评分来完成初筛。
我们需要考虑到,并行化运算时得到的结果矩阵应该是的,代表着所挑选出来的M个表述间共指的评分。通过函数运算时,span嵌入矩阵的大小是的,每个span又需要其他所有span生成共指嵌入矩阵,其大小为.该矩阵经过前馈神经网络即最终得到的评分矩阵。
但是反观,中仅需要处理, 和级别的矩阵的矩阵乘法运算,即可得到最终的评分矩阵,故计算成本更加小。
最终,在筛选潜在先行词时,通过的得分来代替K近邻可以达到既解决了最大共指距离的限制又没有大幅增加计算成本的效果。
2.3 Strengths
提出1.中的span嵌入算法与共指消解的推理是分离的,导致span的嵌入向量更加体现的是局部的特征而非全局特征(locally consistent but globally inconsistent)。即模型在预测span对(A,B)和(B,C)时,并不会考虑到共指消解关系具有传递性,(A,B,C)应该也是和谐的。但是模型并不会考虑这种特性。本文作者引入了Higher-order Coreference Resolution来体现这种特性。

3 BERT for Coreference Resolution: Baselines and Analysis
Joshi et, al. EMNLP 2019 与1同是UW与Facebook实验室的产出
随着大规模预训练模型BERT席卷nlp各项任务成为SOTA,Zettlemoyer团队开始尝试应用BERT模型完成共指消解任务。从结果上来看,在OntoNotes和GAP的基线数据集上的F1值分别提高了3.9和11.5. 本工作同时对比分析了BERT-base、BERT-large、ELMO模型效果的不同。
3.1 问题建模
与1.1和1.2一样
3.2 模型细节
模型基本延续1.2中提出的高阶共指消解模型,记为c2f-coref. 仅有以下两点不同:
使用BERT模型代替原有基于Bi-LSTM和Attention的嵌入模型,使用span中第一个word piece和最后一个word piece的输出向量作为span的嵌入向量。
在使用BERT模型进行嵌入时,由于最大输入长度为512个word pieces的限制,因此如何更好的分割文章成为作者的研究对象。第一种分割方式是独立分割,即文章的每个分割段(segment)作为独立的实例被输入到BERT中。这将导致其中word piece的嵌入向量仅能感知到当前分割段内的信息,并且对于段边缘的词的表达效果并不理想。第二种方式时重叠分割,顾名思义即每个分割段有一半的重叠,使得对段边缘的词拥有更好的表达。重叠的部分通过元素级插值的方式得到最终得嵌入表达。
其中是重叠部分不同的嵌入向量,是可学习的参数矩阵。
3.3 模型评估
在OntoNotes(Document-Level)数据集上的结果:
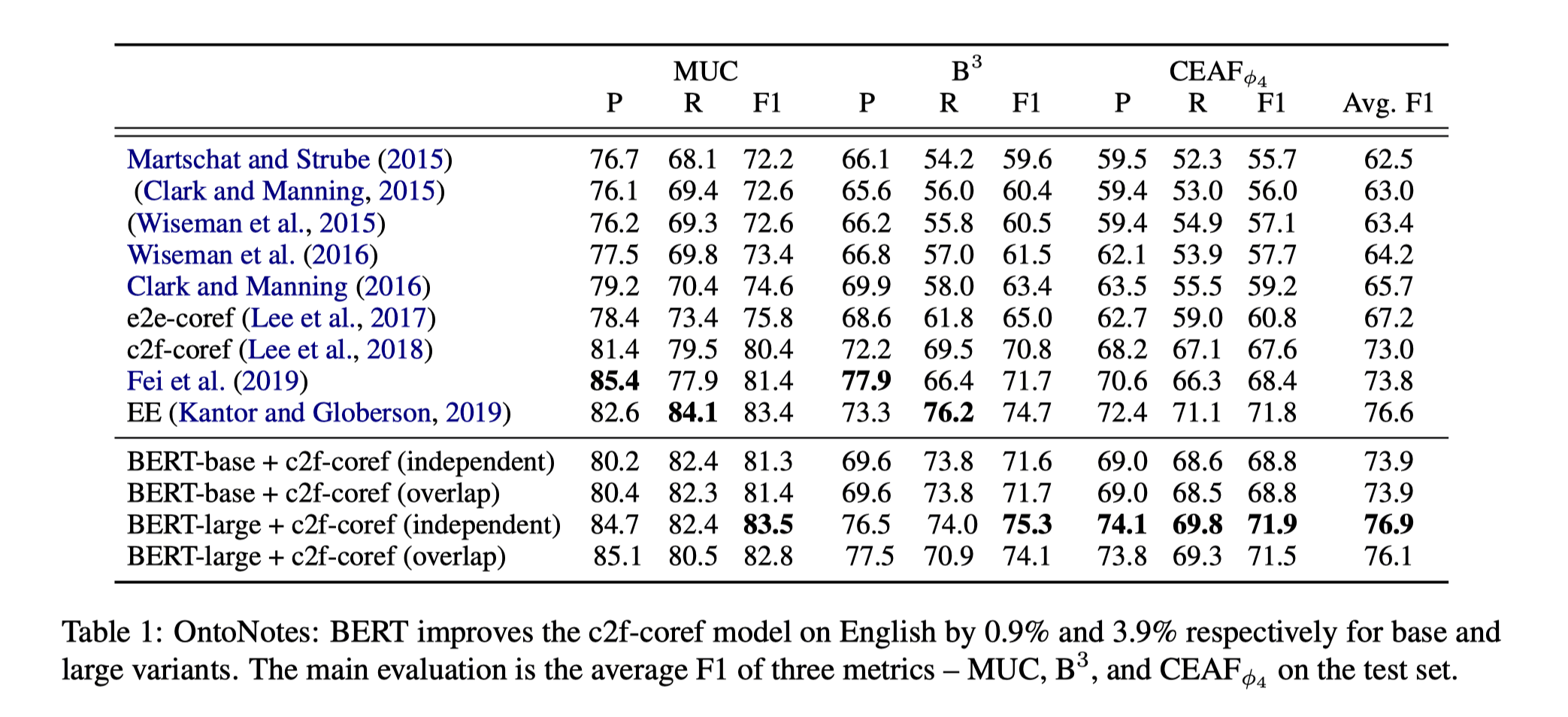
在GAP(Paragraph-Level)数据集上的结果:
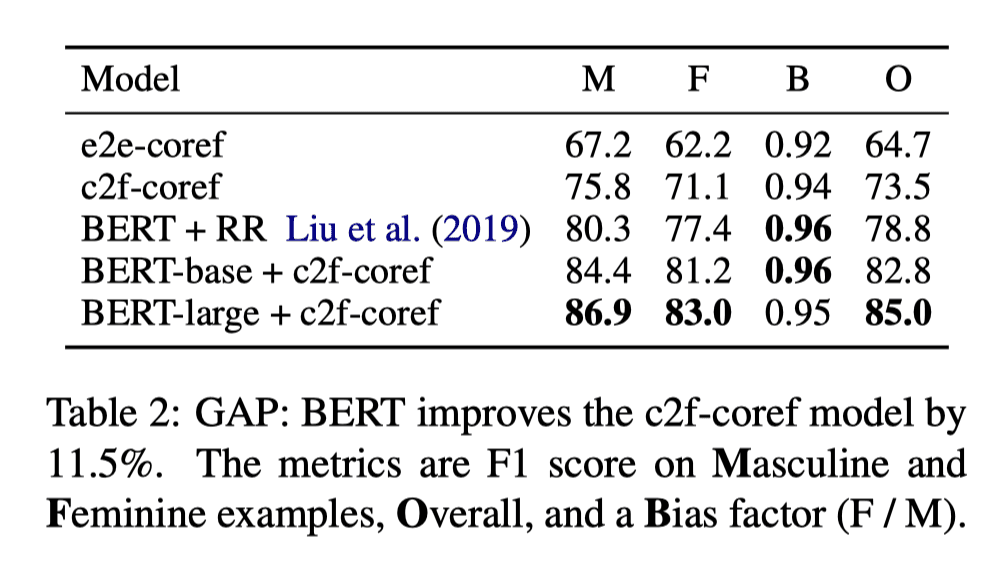
可以看到BERT-large+c2f-coref(independent)的模型表现是最好的。
3.4 Strengths
作者接着细致地对模型的预测进行了勘误,并对比BERT-large与BERT-base模型的区别。

由上图可以看到对于Related Entities(同义实体)和Lexical(语法相关)类型的共指推理,BERT-large模型表现的更出色,犯了更少的错误。在Pronouns(代词)类型的共指推理上,BERT-large模型表现稍好一些,而在Mention Paraphrasing(表述释义)、Conversation(对话)和Misc.(复杂情景)下,BERT-large模型与BERT-base模型都很难处理。
3.5 Weaknesses
通过以下实验,我们可以看到模型在处理长文章时表现欠佳。
由下图可以看出,文章越长模型的所预测的非正确类越多,犯的错误也越多。
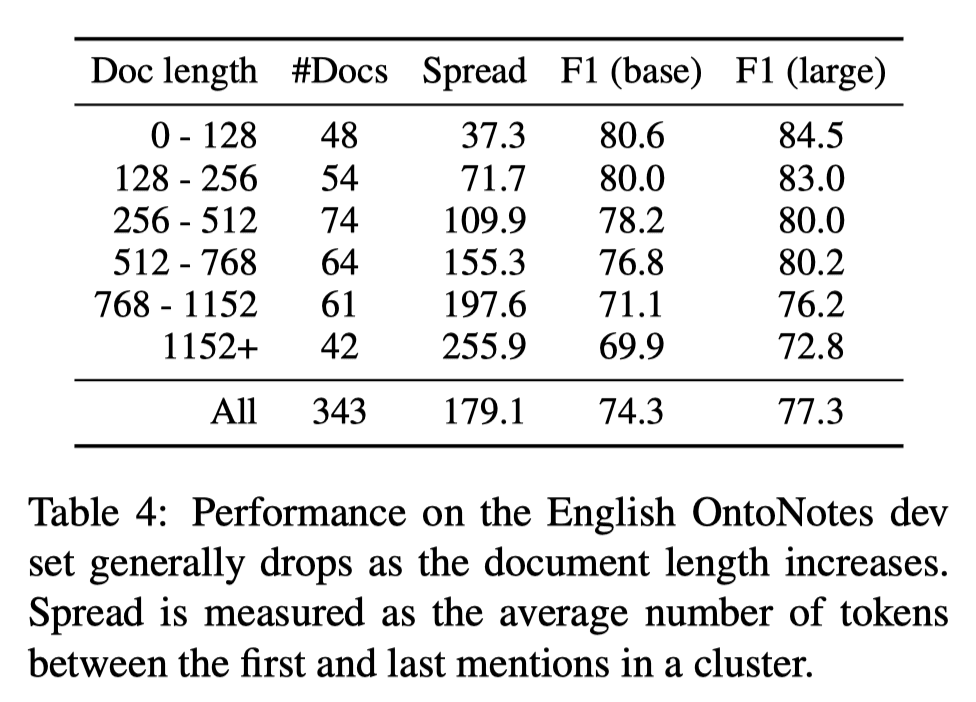
其次,更长的段长度并没有解决问题,反而段长度在450和512时,模型效果不如更短的段长度。作者给出的原因是BERT预训练时使用了更多的短序列,导致其在长序列上表现不佳。
 最后,我们看到使用重叠的分割方式并没有提高模型的表现。
最后,我们看到使用重叠的分割方式并没有提高模型的表现。
所以这给我们的启示是我们需要更有效编码长序列的预训练模型来完成篇章级的共指消解问题。
4 SpanBERT: Improving Pre-training by Representing and Predicting Spans
Joshi et, al. TACL 2019 与上文同是UW与Facebook实验室的产出
J神的又一力作,本文的工作是对BERT的从Token到Span(文本片段)的优化,使其可以更好地预测Span并表达Span含义。不难联想到,上一篇文章使作者对文本中的最小表义单元的表达提出了思考,BERT对于Token级的Mask and Predict的训练方式可能没有更好地体现文本中每个Span的含义。作者提出了两种优化的BERT训练方式:1. 连续随机Span的遮罩和预测;2. 通过Span边缘前后的词语来预测Span的含义。结果发现,SpanBERT在Extractive Question Answering, Coreference Resolution, Relation Extraction和GLUE等多个任务上效果都要比BERT-large要更加出色。可以看到,在大家对BERT模型通过输入更多数据和调整更大的模型尺寸来提高模型表现的时候,Joshi贡献了自己对于设计更好的训练任务和目标的重要性的观点。
4.1 模型细节
作者的SpanBERT使用Span-Level的自训练方法,希望在下游Span Selection Task比如问答系统和共指消解任务上拥有更好的表现。与BERT的自训练任务不同的是,作者改进了遮罩任务的机制并引入了新的SBO(span-boundary objective)学习目标,最后取消了原BERT中的NSP预测任务。
Span Masking
与BERT的MLM任务相同,从token序列中总共选择15%进行遮罩。在每轮的选择中,首先采样span的长度。span的长度服从几何分布(实验中G(0.2)的效果最佳),即,这样使得挑选的span长度偏向于较短的。此外,限制的最大长度为10,所以可以得到平均的应为3.8,即
在确定遮罩span的长度后,作者随机选择某个起始位置进行遮罩,但需要保证span的起始为是一个单词的开头并且被遮罩的span是完整的词而不是词的一部分tokens。
Span Boundary Objective
作者希望通过此任务目标让span的边缘tokens学习到span内部信息,如下图所示。
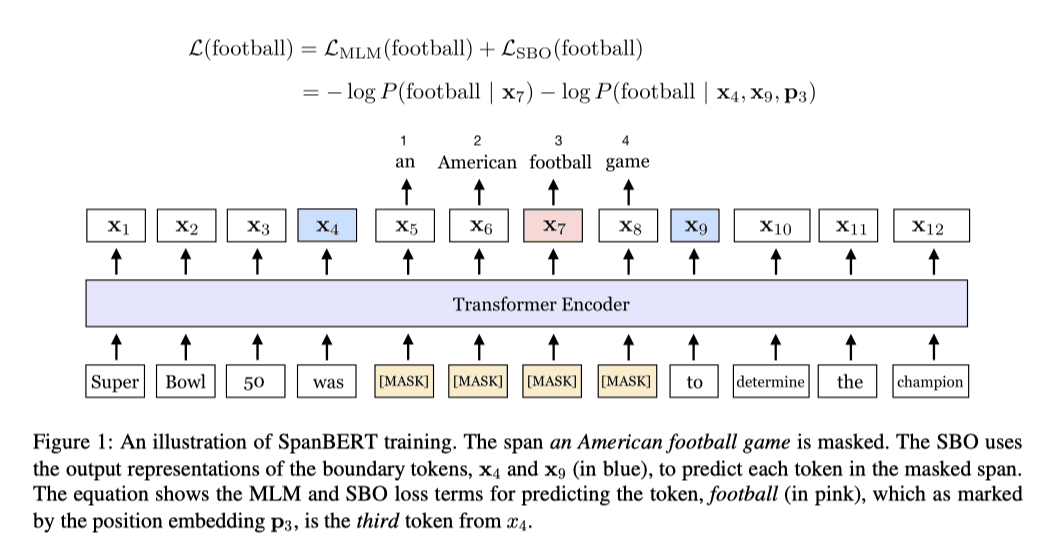
对于输入序列,被遮罩的序列,我们希望通过span边缘的tokens的对应嵌入向量,即和,加上位置嵌入向量得到表示span内部的嵌入向量,使得与由BERT输出的嵌入向量足够相近。
其中,为两层的前馈神经网络搭配GeLU激活函数和层归一化构成。
最后,与计算交叉熵作为Loss。SpanBERT的损失函数为MLM任务和SBO任务损失的和,如下所示:
4.2 模型评估
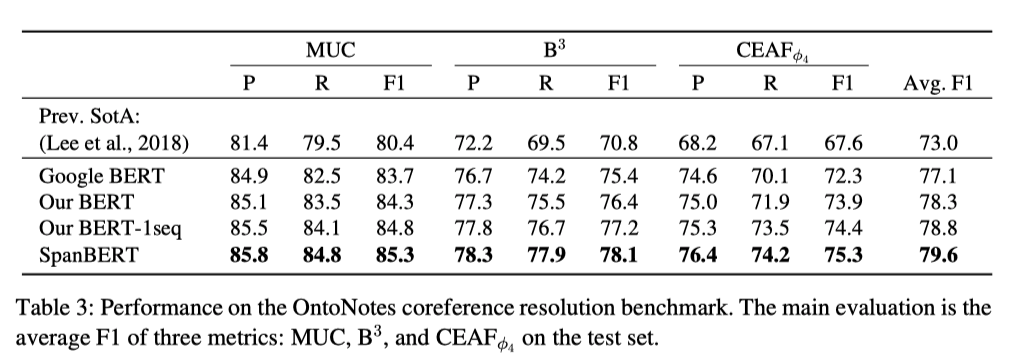
在共指消解任务上,SpanBERT的表现力压Google BERT和原BERT,拥有着最好的效果。
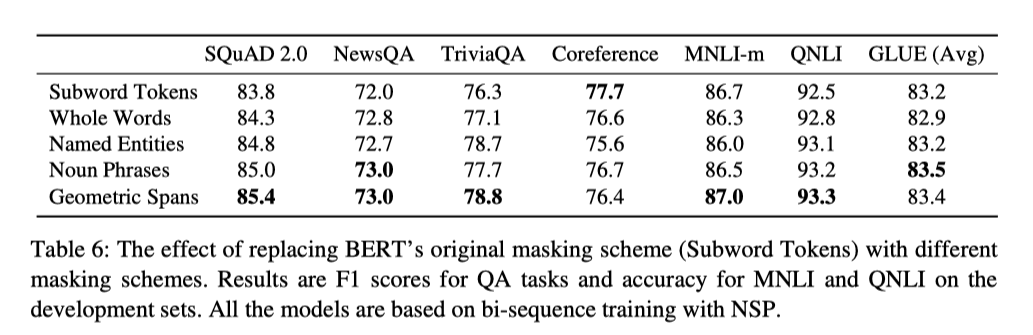
在消融实验中,作者还对比了不同的遮罩机制和不同辅助目标(NSP和SBO)训练下在下游任务上的效果。
对于不同遮罩机制,作者对比了随机Token级遮罩、整词遮罩、实体遮罩、名词短语遮罩、和Span中提出的几何分布遮罩。结果显示基于几何分布的遮罩效果是最优的。
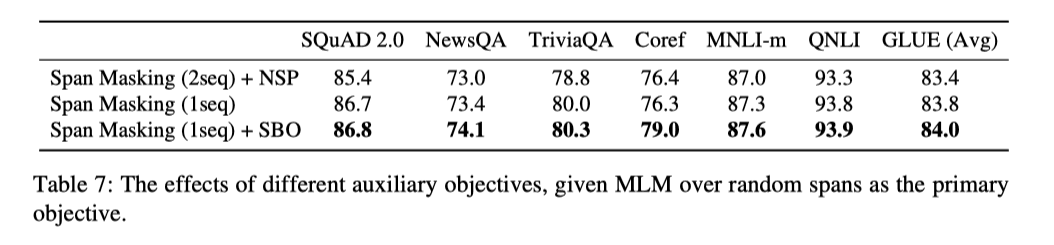
对于辅助任务,SBO搭配Span级MLM有着最好的效果。并且再次印证了单序列输入要比两序列输入拥有更好的效果。
最后,UW实验接下来的在共指消解的工作聚焦于跨文档的共指消解问题,之后如果涉及到了再更新。感谢阅读~