Unlocking Java Fuzzing: All You Wanted to Know About Jazzer
- Published on
Jazzer
0 Overview
Jazzer is a coverage-guided, in-process fuzzer for the JVM platform developed by Code Intelligence. It is based on libFuzzer and brings many of its instrumentation-powered mutation features to the JVM.
libFuzzer
Since Jazzer is built on top of libFuzzer, it's essential to understand libFuzzer's features. libFuzzer is an in-process, coverage-guided fuzz testing tool for C and C++ programs. It was designed to address some limitations of AFL (American Fuzzy Lop), such as:
- AFL originally only accepted inputs from arguments.
- AFL started a new process (out-of-process) for each instance with different input, which could be slower.
The libFuzzer, on the other hand, feeds input directly to a function (acting as an entry point of a library's API) and mutates and calls it repeatedly within the same process. This approach is faster but requires a more restrictive fuzz harness. For more details, refer to the discussion.
libFuzzer requires three components to start fuzzing: the fuzzer library, the target library, and the test driver.
- Fuzzer Library: Contains the
main()function for the entire fuzz testing process. It controls the fuzz loop, including invoking the target harness, collecting feedback, and performing mutations. For libFuzzer, it should be compiled as a static archive. - Target Library: The program to be tested. It needs to be compiled with coverage instrumentation, custom hooks, and sanitizers to provide feedback and capture vulnerabilities.
- Test Driver: A function that calls the library's exposed APIs. The test driver must adhere to certain restrictions.
Finally, we just need to link the three components above and start the fuzzer with a custom initial seed corpus.
Restriction on Fuzz Target (Target Library+Test Driver)
Due to its in-process testing scheme (the harness will be called again and again in the same process), it has certain restrictions:
- It must tolerate any kind of input (empty, huge, malformed, etc).
- It must not exit() on any input.
- It may use threads but ideally all threads should be joined at the end of the function.
- Ideally, it should not modify any global state (although that’s not strict).
- For more, click here.
For the source code of libFuzzer, click here.
Now that we have an understanding of libFuzzer, let's look at Jazzer's design to see how it handles fuzzing software written in Java.
Jazzer
According to its blog, Jazzer want to leverage the libFuzzer out of the box just like it were fuzzing an ordinary native binary. Therefore, Jazzer majorly consist two components:
- Jazzer Driver: a native binary that links in libFuzzer and runs a Java fuzz target through the Java Native Interface (JNI).
- Jazzer Agent: a Java agent that runs in the same JVM as the fuzz target and applies instrumentation at runtime. The information obtained through this instrumentation is fed back to libFuzzer just as it would be for a compile-time instrumented native binary.
To understand more about Jazzer as a fuzzer, let's explore it through the following perspectives: its fuzzing loop, how it collects feedback, its mutation strategy, and its sanitizers.
1 The Fuzzing Loop
Jazzer leverages libFuzzer as its main fuzzing engine, which is written in C++. Consequently, Jazzer operates as a cross-language application where Java and C++ code interact through the Java Native Interface (JNI). This setup can make the codebase a bit complex at first glance.
The entry point of Jazzer is jazzer_main.cpp. It is used to start the JVM properly with the given configuration.
// jazzer/launcher/jazzer_main.cpp
namespace {
const std::string kJazzerClassName = "com/code_intelligence/jazzer/Jazzer";
void StartLibFuzzer(std::unique_ptr<jazzer::JVM> jvm,
std::vector<std::string> argv) {
JNIEnv &env = jvm->GetEnv();
jclass runner = env.FindClass(kJazzerClassName.c_str());
jmethodID startDriver = env.GetStaticMethodID(runner, "main", "([[B)V");
jobjectArray args = env.NewObjectArray(argv.size(), byteArrayClass, nullptr);
env.CallStaticVoidMethod(runner, startDriver, args);
if (env.ExceptionCheck()) {
env.ExceptionDescribe();
}
exit(1);
}
} // namespace
int main(int argc, char **argv) {
StartLibFuzzer(std::unique_ptr<jazzer::JVM>(new jazzer::JVM()),
std::vector<std::string>(argv + 1, argv + argc));
}
Then, instead of starting libFuzzer directly, Jazzer uses a Java wrapper whose entry point is Jazzer.java. This class acts as the libFuzzer-compatible CLI entry point. The wrapper is necessary to configure and verify arguments passed to Jazzer, such as --target-class, and to instrument the current Java process by loading hooks through instrumentation.
During instrumentation and preparation of the fuzz target, custom hooks (e.g., data flow tracing hooks), sanitizer hooks, and code coverage hooks are loaded via the AgentInstaller.install(Opt.hooks.get()); call.
// src/main/java/com/code_intelligence/jazzer/driver/Driver.java
public class Driver {
public static int start(List<String> args, boolean spawnsSubprocesses) throws IOException {
...
AgentInstaller.install(Opt.hooks.get());
FuzzTargetHolder.fuzzTarget = FuzzTargetFinder.findFuzzTarget(targetClassName);
return FuzzTargetRunner.startLibFuzzer(args);
}
}
The call stack before starting the Java Driver is as follows:
runOne:222, FuzzTargetRunner (com.code_intelligence.jazzer.driver)
startLibFuzzer:-1, FuzzTargetRunnerNatives (com.code_intelligence.jazzer.runtime)
startLibFuzzer:541, FuzzTargetRunner (com.code_intelligence.jazzer.driver)
startLibFuzzer:431, FuzzTargetRunner (com.code_intelligence.jazzer.driver)
start:153, Driver (com.code_intelligence.jazzer.driver)
start:115, Jazzer (com.code_intelligence.jazzer)
main:74, Jazzer (com.code_intelligence.jazzer)
/**
* The native functions used by FuzzTargetRunner.
*
* <p>This class has to be loaded by the bootstrap class loader since the native library it loads
* links in libFuzzer and the Java hooks, which have to be on the bootstrap path so that they are
* seen by Java standard library classes, need to be able to call native libFuzzer callbacks.
*/
public class FuzzTargetRunnerNatives {
static {
...
RulesJni.loadLibrary("jazzer_driver", "/com/code_intelligence/jazzer/driver");
}
public static native int startLibFuzzer(
byte[][] args, Class<?> runner, boolean useExperimentalMutator);
public static native void printAndDumpCrashingInput();
public static native void temporarilyDisableLibfuzzerExitHook();
}
The code under jazzer/src/main/native/com/code_intelligence/jazzer/driver is the Java Driver, which will be invoked through the FuzzTargetRunner function above. The Java Driver serves as a bridge between the fuzz target, feedback mechanisms, and mutation algorithms written in Java, and libFuzzer, which is written in C++. This means that all custom callback functions expected by libFuzzer are implemented in the Jazzer Driver and call the corresponding Java functions through JNI.
Java_com_code_1intelligence_jazzer_runtime_FuzzTargetRunnerNatives_startLibFuzzer(
JNIEnv *env, jclass, jobjectArray args, jclass runner,
jboolean useExperimentalMutator) {
gUseExperimentalMutator = useExperimentalMutator;
gEnv = env;
env->GetJavaVM(&gJavaVm);
gRunner = reinterpret_cast<jclass>(env->NewGlobalRef(runner));
gRunOneId = env->GetStaticMethodID(runner, "runOne", "(JI)I");
gMutateOneId = env->GetStaticMethodID(runner, "mutateOne", "(JIII)I");
gCrossOverId = env->GetStaticMethodID(runner, "crossOver", "(JIJIJII)I");
if (gRunOneId == nullptr) {
env->ExceptionDescribe();
_Exit(1);
}
int argc = env->GetArrayLength(args);
if (env->ExceptionCheck()) {
env->ExceptionDescribe();
_Exit(1);
}
std::vector<std::string> argv_strings;
std::vector<const char *> argv_c;
for (jsize i = 0; i < argc; i++) {
auto arg_jni =
reinterpret_cast<jbyteArray>(env->GetObjectArrayElement(args, i));
if (arg_jni == nullptr) {
env->ExceptionDescribe();
_Exit(1);
}
jbyte *arg_c = env->GetByteArrayElements(arg_jni, nullptr);
if (arg_c == nullptr) {
env->ExceptionDescribe();
_Exit(1);
}
std::size_t arg_size = env->GetArrayLength(arg_jni);
if (env->ExceptionCheck()) {
env->ExceptionDescribe();
_Exit(1);
}
argv_strings.emplace_back(reinterpret_cast<const char *>(arg_c), arg_size);
env->ReleaseByteArrayElements(arg_jni, arg_c, JNI_ABORT);
if (env->ExceptionCheck()) {
env->ExceptionDescribe();
_Exit(1);
}
}
for (jsize i = 0; i < argc; i++) {
argv_c.emplace_back(argv_strings[i].c_str());
}
// Null-terminate argv.
argv_c.emplace_back(nullptr);
const char **argv = argv_c.data();
return LLVMFuzzerRunDriver(&argc, const_cast<char ***>(&argv), testOneInput);
}
The function LLVMFuzzerRunDriver starts libFuzzer within the fuzz_target_runner.cpp file. After passing the control to libFuzzer, we competed the preparation stage and start the real fuzzing loop! The following function calls in Jazzer act as callbacks. For example, to run the fuzz harness, libFuzzer will call the testOneInput function in the Fuzz Driver, which in turn calls the Java-written fuzz harness.
int testOneInput(const uint8_t *data, const std::size_t size) {
JNIEnv &env = *gEnv;
jint jsize = std::min(size, static_cast<size_t>(std::numeric_limits<jint>::max()));
int res = env.CallStaticIntMethod(gRunner, gRunOneId, data, jsize);
if (env.ExceptionCheck()) {
env.ExceptionDescribe();
_Exit(1);
}
return res;
}
And in the Java world, the following function will be invoked.
/**
* Executes the user-provided fuzz target once.
*
* @param dataPtr a native pointer to the beginning of the input provided by the fuzzer for this
* execution
* @param dataLength length of the fuzzer input
* @return the value that the native LLVMFuzzerTestOneInput function should return. The function
* may exit the process instead of returning.
*/
private static int runOne(long dataPtr, int dataLength) {
Throwable finding = null;
byte[] data;
Object argument;
Object fuzzTargetInstance = lifecycleMethodsInvoker.getTestClassInstance();
...
if (useExperimentalMutator) {
mutator.invoke(fuzzTargetInstance, false);
} else if (fuzzTargetInstance == null) {
fuzzTargetMethod.invoke(argument);
} else {
fuzzTargetMethod.invoke(fuzzTargetInstance, argument);
}
...
}
2 Feedbacks
During the fuzzing loop, feedback information is collected through callback functions inserted into the program during the instrumentation stage. For libFuzzer and Jazzer, these callbacks help trace the control flow and data flow. In this section, we will discuss where these callbacks are inserted and what kinds of information are collected.
2.1 Tracing Control-flow
For libFuzzer, it leverages the SanitizerCoverage pass in LLVM during compilation, allowing users to insert calls to user-defined functions at the function, basic block, and edge levels. More detailed information about SanitizerCoverage can be found in this link.
libFuzzer uses the PC-Table with Inline 8-bit counters for edge-level coverage. It also tracks indirect function calls that are not traceable during compilation time. The output of the PC Table is an array of pointer-sized integers representing pairs [PC, PCFlags] for every instrumented block in the module (DSO library). The output of Inline 8-bit counters is an array of 8-bit counters for each edge (Instrumented PCs) which will be updated by the LLVM inserted inline 8-bit counters on every hits.
// https://github.com/llvm/llvm-project/blob/0280f97b36c83a7129e5dbce53c603b7ec5d82fe/compiler-rt/lib/fuzzer/FuzzerTracePC.cpp#L463C1-L479C2
ATTRIBUTE_INTERFACE
void __sanitizer_cov_8bit_counters_init(uint8_t *Start, uint8_t *Stop) {
fuzzer::TPC.HandleInline8bitCountersInit(Start, Stop);
}
ATTRIBUTE_INTERFACE
void __sanitizer_cov_pcs_init(const uintptr_t *pcs_beg,
const uintptr_t *pcs_end) {
fuzzer::TPC.HandlePCsInit(pcs_beg, pcs_end);
}
ATTRIBUTE_INTERFACE
ATTRIBUTE_NO_SANITIZE_ALL
void __sanitizer_cov_trace_pc_indir(uintptr_t Callee) {
uintptr_t PC = reinterpret_cast<uintptr_t>(GET_CALLER_PC());
fuzzer::TPC.HandleCallerCallee(PC, Callee);
}
libFuzzer gains code coverage information from the SanitizerCoverage pass. During runtime, the SanitizerCoverage-instrumented code will call __sanitizer_cov_8bit_counters_init and __sanitizer_cov_pcs_init to let libFuzzer access the program's coverage. Similarly, for the java fuzz target, we use Jacoco to instrument the java program and pass the coverage information to the libFuzzer by calling the same functions. This part of the code is within this file.
2.2 Tracing Data-flow
Besides tracing control-flow through edge coverage, libFuzzer and Jazzer also support data-flow operations to provide more useful information. For libFuzzer, it tracks CMP instructions using the compiler flag -fsanitize-coverage=trace-cmp. Additionally, with the runtime flag -use_value_profile=1, the fuzzer collects value profiles for the parameters of compare instructions and treats some new values as new coverage.
With the -fsanitize-coverage=trace-cmp compilation flag, SanitizerCoverage captures the following comparison-related operations:
// https://clang.llvm.org/docs/SanitizerCoverage.html#tracing-data-flow
// Called before a comparison instruction.
// Arg1 and Arg2 are arguments of the comparison.
void __sanitizer_cov_trace_cmp1(uint8_t Arg1, uint8_t Arg2);
void __sanitizer_cov_trace_cmp2(uint16_t Arg1, uint16_t Arg2);
void __sanitizer_cov_trace_cmp4(uint32_t Arg1, uint32_t Arg2);
void __sanitizer_cov_trace_cmp8(uint64_t Arg1, uint64_t Arg2);
// Called before a comparison instruction if exactly one of the arguments is constant.
// Arg1 and Arg2 are arguments of the comparison, Arg1 is a compile-time constant.
// These callbacks are emitted by -fsanitize-coverage=trace-cmp since 2017-08-11
void __sanitizer_cov_trace_const_cmp1(uint8_t Arg1, uint8_t Arg2);
void __sanitizer_cov_trace_const_cmp2(uint16_t Arg1, uint16_t Arg2);
void __sanitizer_cov_trace_const_cmp4(uint32_t Arg1, uint32_t Arg2);
void __sanitizer_cov_trace_const_cmp8(uint64_t Arg1, uint64_t Arg2);
// Called before a switch statement.
// Val is the switch operand.
// Cases[0] is the number of case constants.
// Cases[1] is the size of Val in bits.
// Cases[2:] are the case constants.
void __sanitizer_cov_trace_switch(uint64_t Val, uint64_t *Cases);
// Called before a division statement.
// Val is the second argument of division.
void __sanitizer_cov_trace_div4(uint32_t Val);
void __sanitizer_cov_trace_div8(uint64_t Val);
// Called before a GetElemementPtr (GEP) instruction
// for every non-constant array index.
void __sanitizer_cov_trace_gep(uintptr_t Idx);
libFuzzer treats these operations as additional coverage information. The process works roughly as follows (according to the document):
- The compiler instruments all CMP instructions with a callback that receives both CMP arguments.
- The callback computes
(caller_pc & 4095) | (popcnt(Arg1 ^ Arg2) << 12)and uses this value to set a bit in a bitset. - Every new observed bit in the bitset is treated as new coverage.
/ /https://github.com/llvm/llvm-project/blob/main/compiler-rt/lib/fuzzer/FuzzerTracePC.cpp#L383
template <class T>
ATTRIBUTE_TARGET_POPCNT ALWAYS_INLINE
ATTRIBUTE_NO_SANITIZE_ALL
void TracePC::HandleCmp(uintptr_t PC, T Arg1, T Arg2) {
uint64_t ArgXor = Arg1 ^ Arg2;
if (sizeof(T) == 4)
TORC4.Insert(ArgXor, Arg1, Arg2);
else if (sizeof(T) == 8)
TORC8.Insert(ArgXor, Arg1, Arg2);
uint64_t HammingDistance = Popcountll(ArgXor); // [0,64]
uint64_t AbsoluteDistance = (Arg1 == Arg2 ? 0 : Clzll(Arg1 - Arg2) + 1);
ValueProfileMap.AddValue(PC * 128 + HammingDistance);
ValueProfileMap.AddValue(PC * 128 + 64 + AbsoluteDistance);
}
Besides the above operations, the libFuzzer also applies the custom hooks on string/memory comparison related glibc function calls, during the initial stage. And these information will also be collected during runtime with the customized hooks. Detailed information about these custom hooks can be found here. The following code shows which functions have been hooked by libFuzzer:
// https://github.com/llvm/llvm-project/blob/main/compiler-rt/lib/fuzzer/FuzzerInterceptors.cpp
REAL(bcmp) = reinterpret_cast<memcmp_type>(
getFuncAddr("bcmp", reinterpret_cast<uintptr_t>(&bcmp)));
REAL(memcmp) = reinterpret_cast<memcmp_type>(
getFuncAddr("memcmp", reinterpret_cast<uintptr_t>(&memcmp)));
REAL(strncmp) = reinterpret_cast<strncmp_type>(
getFuncAddr("strncmp", reinterpret_cast<uintptr_t>(&strncmp)));
REAL(strcmp) = reinterpret_cast<strcmp_type>(
getFuncAddr("strcmp", reinterpret_cast<uintptr_t>(&strcmp)));
REAL(strncasecmp) = reinterpret_cast<strncasecmp_type>(
getFuncAddr("strncasecmp", reinterpret_cast<uintptr_t>(&strncasecmp)));
REAL(strcasecmp) = reinterpret_cast<strcasecmp_type>(
getFuncAddr("strcasecmp", reinterpret_cast<uintptr_t>(&strcasecmp)));
REAL(strstr) = reinterpret_cast<strstr_type>(
getFuncAddr("strstr", reinterpret_cast<uintptr_t>(&strstr)));
REAL(strcasestr) = reinterpret_cast<strcasestr_type>(
getFuncAddr("strcasestr", reinterpret_cast<uintptr_t>(&strcasestr)));
REAL(memmem) = reinterpret_cast<memmem_type>(
getFuncAddr("memmem", reinterpret_cast<uintptr_t>(&memmem)));
Similarly, in Jazzer, it instruments the native Java bytecodes and hooks a large list of built-in functions in Java for string or memory comparison at runtime to provide similar feedback for libFuzzer. For bytecodes, the detailed list of hooked opcodes can be found here. For built-in functions, the detailed list of hooked functions can be found here. With the runtime flag -use_value_profile=1, the information collected by these hooks will be used as code coverage.
For the usage of this information, Jazzer adopts how libFuzzer handles these values. For example, for the String.contentEquals function, it passes the argument and the compared string object to the traceMemcmp function, which is implemented in FuzzerTracePC.cpp in libFuzzer.
// https://github.com/CodeIntelligenceTesting/jazzer/blob/d2cbfdcfc5363593f36cd972b849cc3ab070c90a/src/main/java/com/code_intelligence/jazzer/runtime/TraceCmpHooks.java
@MethodHook(
type = HookType.AFTER,
targetClassName = "java.lang.String",
targetMethod = "contentEquals")
public static void contentEquals(
MethodHandle method,
String thisObject,
Object[] arguments,
int hookId,
Boolean areEqualContents) {
if (!areEqualContents && arguments.length == 1 && arguments[0] instanceof CharSequence) {
TraceDataFlowNativeCallbacks.traceStrcmp(
thisObject, ((CharSequence) arguments[0]).toString(), 1, hookId);
}
In this example, when the contentEquals method is called, if the contents are not equal and the argument is a CharSequence, Jazzer calls traceStrcmp, which in turn calls traceMemcmp.
// https://github.com/CodeIntelligenceTesting/jazzer/blob/d2cbfdcfc5363593f36cd972b849cc3ab070c90a/src/main/java/com/code_intelligence/jazzer/runtime/TraceDataFlowNativeCallbacks.java
public final class TraceDataFlowNativeCallbacks {
static {
RulesJni.loadLibrary("jazzer_driver", "/com/code_intelligence/jazzer/driver");
}
public static native void traceMemcmp(byte[] b1, byte[] b2, int result, int pc);
public static void traceStrcmp(String s1, String s2, int result, int pc) {
if (NATIVE_INITIALIZED) {
traceMemcmp(encodeForLibFuzzer(s1), encodeForLibFuzzer(s2), result, pc);
}
}
}
2.3 TORC and ValuebitMap
o better utilize feedback, libFuzzer employs two key data structures: TableOfRecentCompares (TORC) and ValueBitMap. TORC remembers the most recently seen values during the fuzzing process, effectively acting as a runtime-collected dictionary. The ValueBitMap converts comparison results into coverage information, allowing the fuzzer to determine if it is getting closer to passing the comparison.
// TableOfRecentCompares (TORC) remembers the most recently performed
// comparisons of type T.
// We record the arguments of CMP instructions in this table unconditionally
// because it seems cheaper this way than to compute some expensive
// conditions inside __sanitizer_cov_trace_cmp*.
// After the unit has been executed we may decide to use the contents of
// this table to populate a Dictionary.
template<class T, size_t kSizeT>
struct TableOfRecentCompares {
static const size_t kSize = kSizeT;
struct Pair {
T A, B;
};
ATTRIBUTE_NO_SANITIZE_ALL
void Insert(size_t Idx, const T &Arg1, const T &Arg2) {
Idx = Idx % kSize;
Table[Idx].A = Arg1;
Table[Idx].B = Arg2;
}
Pair Get(size_t I) { return Table[I % kSize]; }
Pair Table[kSize];
};
template <size_t kSizeT>
struct MemMemTable {
static const size_t kSize = kSizeT;
Word MemMemWords[kSize];
Word EmptyWord;
void Add(const uint8_t *Data, size_t Size) {
if (Size <= 2) return;
Size = std::min(Size, Word::GetMaxSize());
auto Idx = SimpleFastHash(Data, Size) % kSize;
MemMemWords[Idx].Set(Data, Size);
}
const Word &Get(size_t Idx) {
for (size_t i = 0; i < kSize; i++) {
const Word &W = MemMemWords[(Idx + i) % kSize];
if (W.size()) return W;
}
EmptyWord.Set(nullptr, 0);
return EmptyWord;
}
};
struct ValueBitMap {
static const size_t kMapSizeInBits = 1 << 16;
static const size_t kMapPrimeMod = 65371; // Largest Prime < kMapSizeInBits;
static const size_t kBitsInWord = (sizeof(uintptr_t) * 8);
static const size_t kMapSizeInWords = kMapSizeInBits / kBitsInWord;
public:
// Clears all bits.
void Reset() { memset(Map, 0, sizeof(Map)); }
// Computes a hash function of Value and sets the corresponding bit.
// Returns true if the bit was changed from 0 to 1.
ATTRIBUTE_NO_SANITIZE_ALL
inline bool AddValue(uintptr_t Value) {
uintptr_t Idx = Value % kMapSizeInBits;
uintptr_t WordIdx = Idx / kBitsInWord;
uintptr_t BitIdx = Idx % kBitsInWord;
uintptr_t Old = Map[WordIdx];
uintptr_t New = Old | (1ULL << BitIdx);
Map[WordIdx] = New;
return New != Old;
}
};
For CMP opcodes, libFuzzer places the left and right operands into the TORC table and also inserts the program counter (PC) and current distance into the ValueProfileMap.
template <class T>
ATTRIBUTE_TARGET_POPCNT ALWAYS_INLINE
ATTRIBUTE_NO_SANITIZE_ALL
void TracePC::HandleCmp(uintptr_t PC, T Arg1, T Arg2) {
uint64_t ArgXor = Arg1 ^ Arg2;
if (sizeof(T) == 4)
TORC4.Insert(ArgXor, Arg1, Arg2);
else if (sizeof(T) == 8)
TORC8.Insert(ArgXor, Arg1, Arg2);
uint64_t HammingDistance = Popcountll(ArgXor); // [0,64]
uint64_t AbsoluteDistance = (Arg1 == Arg2 ? 0 : Clzll(Arg1 - Arg2) + 1);
ValueProfileMap.AddValue(PC * 128 + HammingDistance);
ValueProfileMap.AddValue(PC * 128 + 64 + AbsoluteDistance);
}
3 Mutation
In this section, we describe the mutation algorithm used in Jazzer (libFuzzer).
libFuzzer do the mutation on byte streams. The mutation algorithms can be found at this file.
MutationDispatcher::MutationDispatcher(Random &Rand,
const FuzzingOptions &Options)
: Rand(Rand), Options(Options) {
DefaultMutators.insert(
DefaultMutators.begin(),
{
{&MutationDispatcher::Mutate_EraseBytes, "EraseBytes"},
{&MutationDispatcher::Mutate_InsertByte, "InsertByte"},
{&MutationDispatcher::Mutate_InsertRepeatedBytes,
"InsertRepeatedBytes"},
{&MutationDispatcher::Mutate_ChangeByte, "ChangeByte"},
{&MutationDispatcher::Mutate_ChangeBit, "ChangeBit"},
{&MutationDispatcher::Mutate_ShuffleBytes, "ShuffleBytes"},
{&MutationDispatcher::Mutate_ChangeASCIIInteger, "ChangeASCIIInt"},
{&MutationDispatcher::Mutate_ChangeBinaryInteger, "ChangeBinInt"},
{&MutationDispatcher::Mutate_CopyPart, "CopyPart"},
{&MutationDispatcher::Mutate_CrossOver, "CrossOver"},
{&MutationDispatcher::Mutate_AddWordFromManualDictionary,
"ManualDict"},
{&MutationDispatcher::Mutate_AddWordFromPersistentAutoDictionary,
"PersAutoDict"},
});
if(Options.UseCmp)
DefaultMutators.push_back(
{&MutationDispatcher::Mutate_AddWordFromTORC, "CMP"});
if (EF->LLVMFuzzerCustomMutator)
Mutators.push_back({&MutationDispatcher::Mutate_Custom, "Custom"});
else
Mutators = DefaultMutators;
if (EF->LLVMFuzzerCustomCrossOver)
Mutators.push_back(
{&MutationDispatcher::Mutate_CustomCrossOver, "CustomCrossOver"});
}
Most of the mutation strategy is understand from the function name. Here we only describe the CrossOver , PersAutoDict and CMP.
CrossOver
The CrossOver mutation strategy combines parts of two different inputs to create a new one. In Mutate_CrossOver, if the size constraints are met, the method selects a second input (CrossOverWith) and performs one of three operations: combining segments from both inputs, inserting parts of the second input into the first, or copying parts of the second input over the first.
size_t MutationDispatcher::Mutate_CrossOver(uint8_t *Data, size_t Size,
size_t MaxSize) {
if (Size > MaxSize) return 0;
if (Size == 0) return 0;
if (!CrossOverWith) return 0;
const Unit &O = *CrossOverWith;
if (O.empty()) return 0;
size_t NewSize = 0;
switch(Rand(3)) {
case 0:
MutateInPlaceHere.resize(MaxSize);
NewSize = CrossOver(Data, Size, O.data(), O.size(),
MutateInPlaceHere.data(), MaxSize);
memcpy(Data, MutateInPlaceHere.data(), NewSize);
break;
case 1:
NewSize = InsertPartOf(O.data(), O.size(), Data, Size, MaxSize);
if (!NewSize)
NewSize = CopyPartOf(O.data(), O.size(), Data, Size);
break;
case 2:
NewSize = CopyPartOf(O.data(), O.size(), Data, Size);
break;
default: assert(0);
}
assert(NewSize > 0 && "CrossOver returned empty unit");
assert(NewSize <= MaxSize && "CrossOver returned overisized unit");
return NewSize;
}
PersAutoDict
The PersAutoDict mutation strategy uses a persistent auto-dictionary to guide mutations. This strategy involves adding words from a dictionary that has been built up from successful mutations during the fuzzing process. The Mutate_AddWordFromPersistentAutoDictionary function selects a random entry from this dictionary and inserts it into the current input. If the mutation results in a new coverage or successful test case, the dictionary entry's success count is increased, and it is added to the PersistentAutoDictionary if not already present. This strategy leverage the control-flow and data-flow coverage.
size_t MutationDispatcher::Mutate_AddWordFromPersistentAutoDictionary(
uint8_t *Data, size_t Size, size_t MaxSize) {
return AddWordFromDictionary(PersistentAutoDictionary, Data, Size, MaxSize);
}
size_t MutationDispatcher::AddWordFromDictionary(Dictionary &D, uint8_t *Data,
size_t Size, size_t MaxSize) {
if (Size > MaxSize) return 0;
if (D.empty()) return 0;
DictionaryEntry &DE = D[Rand(D.size())];
Size = ApplyDictionaryEntry(Data, Size, MaxSize, DE);
if (!Size) return 0;
DE.IncUseCount();
CurrentDictionaryEntrySequence.push_back(&DE);
return Size;
}
void Fuzzer::ReportNewCoverage(InputInfo *II, const Unit &U) {
II->NumSuccessfullMutations++;
MD.RecordSuccessfulMutationSequence();
PrintStatusForNewUnit(U, II->Reduced ? "REDUCE" : "NEW ");
WriteToOutputCorpus(U);
NumberOfNewUnitsAdded++;
CheckExitOnSrcPosOrItem(); // Check only after the unit is saved to corpus.
LastCorpusUpdateRun = TotalNumberOfRuns;
}
// Copy successful dictionary entries to PersistentAutoDictionary.
void MutationDispatcher::RecordSuccessfulMutationSequence() {
for (auto DE : CurrentDictionaryEntrySequence) {
// PersistentAutoDictionary.AddWithSuccessCountOne(DE);
DE->IncSuccessCount();
assert(DE->GetW().size());
// Linear search is fine here as this happens seldom.
if (!PersistentAutoDictionary.ContainsWord(DE->GetW()))
PersistentAutoDictionary.push_back(*DE);
}
}
CMP
The CMP mutation strategy leverages comparisons tracked during execution to guide mutations. The Mutate_AddWordFromTORC function retrieves recent comparison pairs from the TableOfRecentCompares (TORC) and constructs dictionary entries from them. These entries are then applied to the current input, increasing the chances of passing comparisons that were previously close.
size_t MutationDispatcher::Mutate_AddWordFromTORC(
uint8_t *Data, size_t Size, size_t MaxSize) {
Word W;
DictionaryEntry DE;
switch (Rand(4)) {
case 0: {
auto X = TPC.TORC8.Get(Rand.Rand<size_t>());
DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size);
} break;
case 1: {
auto X = TPC.TORC4.Get(Rand.Rand<size_t>());
if ((X.A >> 16) == 0 && (X.B >> 16) == 0 && Rand.RandBool())
DE = MakeDictionaryEntryFromCMP((uint16_t)X.A, (uint16_t)X.B, Data, Size);
else
DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size);
} break;
case 2: {
auto X = TPC.TORCW.Get(Rand.Rand<size_t>());
DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size);
} break;
case 3: if (Options.UseMemmem) {
auto X = TPC.MMT.Get(Rand.Rand<size_t>());
DE = DictionaryEntry(X);
} break;
default:
assert(0);
}
if (!DE.GetW().size()) return 0;
Size = ApplyDictionaryEntry(Data, Size, MaxSize, DE);
if (!Size) return 0;
DictionaryEntry &DERef =
CmpDictionaryEntriesDeque[CmpDictionaryEntriesDequeIdx++ %
kCmpDictionaryEntriesDequeSize];
DERef = DE;
CurrentDictionaryEntrySequence.push_back(&DERef);
return Size;
}
Besides the mutation strategies provided by libFuzzer, Jazzer also offers a custom mutation algorithm when the --experimental_mutator flag is set, as specified in this file. This custom mutator combines different mutation strategies to handle various data types more effectively.
// https://github.com/CodeIntelligenceTesting/jazzer/blob/main/src/main/java/com/code_intelligence/jazzer/mutation/mutator/Mutators.java
public static MutatorFactory newFactory() {
return new ChainedMutatorFactory(
LangMutators.newFactory(),
CollectionMutators.newFactory(),
ProtoMutators.newFactory(),
LibFuzzerMutators.newFactory());
}
The mutation strategy of libFuzzer operates at the byte level and ignores the specific data types used by the fuzz harness, which can lead to less effective mutations. In contrast, Jazzer's custom mutators handle different data types differently, enhancing the effectiveness of the mutations. For instance, LangMutators handles various data types such as booleans, floating points, integers, byte arrays, strings, and enums. While, CollectionMutators is designed to mutate complex data structures like lists and maps, ensuring that mutations are relevant and effective for these types.
public final class LangMutators {
private LangMutators() {}
public static MutatorFactory newFactory() {
return new ChainedMutatorFactory(
new NullableMutatorFactory(),
new BooleanMutatorFactory(),
new FloatingPointMutatorFactory(),
new IntegralMutatorFactory(),
new ByteArrayMutatorFactory(),
new StringMutatorFactory(),
new EnumMutatorFactory());
}
}
public final class CollectionMutators {
private CollectionMutators() {}
public static MutatorFactory newFactory() {
return new ChainedMutatorFactory(new ListMutatorFactory(), new MapMutatorFactory());
}
}
In additional, Jazzer also has custom algorithm to guide input stream to the serialized format of jaz.Zer class for Java Deserialization vulnerability.
// https://github.com/CodeIntelligenceTesting/jazzer/blob/d2cbfdcfc5363593f36cd972b849cc3ab070c90a/sanitizers/src/main/java/com/code_intelligence/jazzer/sanitizers/Utils.kt#L49
internal fun guideMarkableInputStreamTowardsEquality(stream: InputStream, target: ByteArray, id: Int) {
fun readBytes(stream: InputStream, size: Int): ByteArray {
val current = ByteArray(size)
var n = 0
while (n < size) {
val count = stream.read(current, n, size - n)
if (count < 0) break
n += count
}
return current
}
check(stream.markSupported())
stream.mark(target.size)
val current = readBytes(stream, target.size)
stream.reset()
Jazzer.guideTowardsEquality(current, target, id)
}
4 Sanitizers
All supported sanitizers are listed here. They include Deserialization Vulnerability, Expression Language Injection, Ldap Injection, Naming Context Injection, Os Command Injection, SQL Injection, Server Side Request Forgery, XPath Injection, and Regex Injection. However, Jazzer does not support vulnerabilities like Reflected XSS, which require interaction with the browser. Users can define the vulnerable state of their program and raise the FuzzerSecurityIssueHigh, FuzzerSecurityIssueMedium, or FuzzerSecurityIssueLow exceptions to indicate different levels of security concerns.
5 Debugging
Build
https://github.com/CodeIntelligenceTesting/jazzer/blob/main/CONTRIBUTING.md
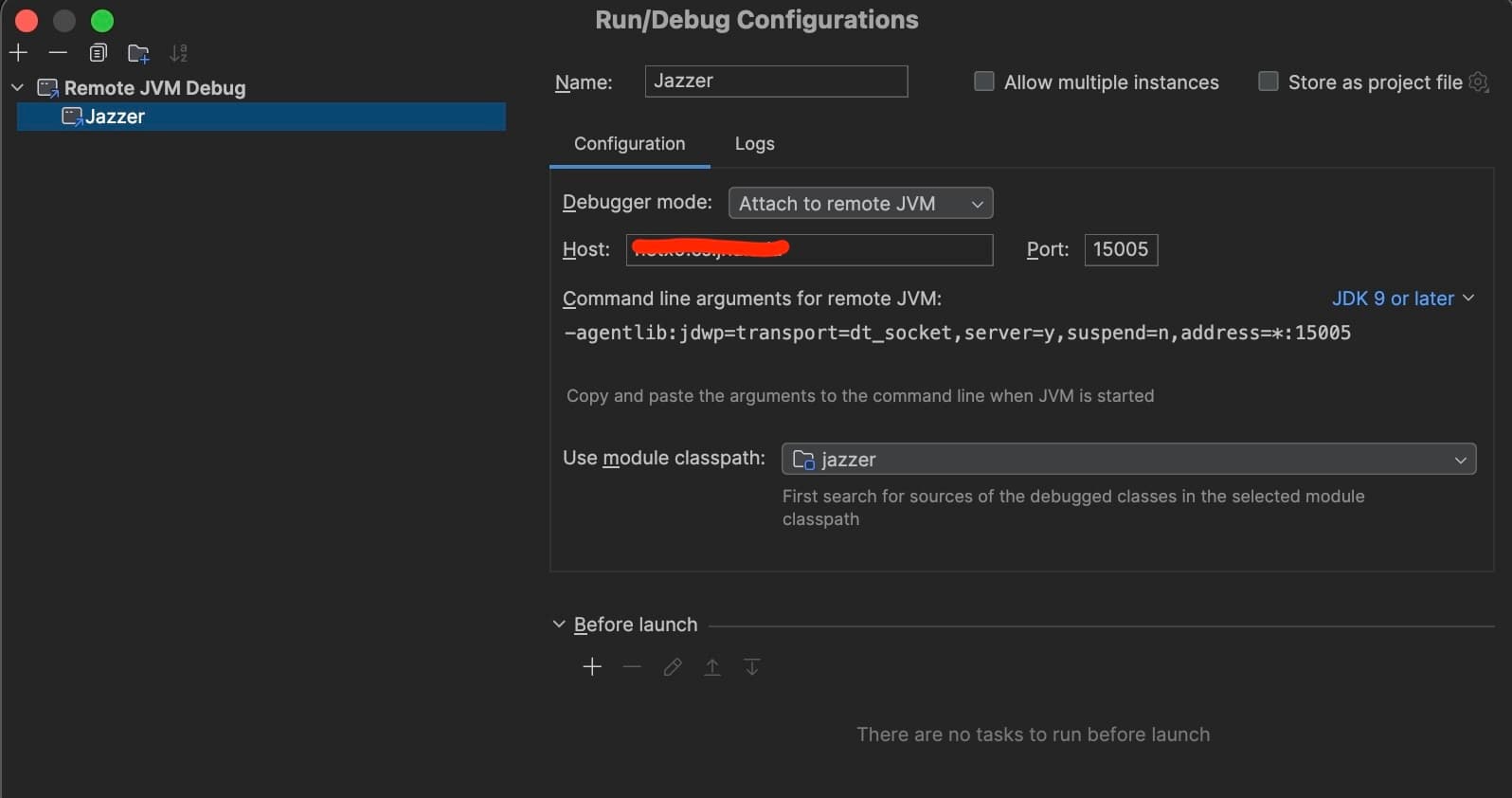
Debug
The configuration on the server side to start the Jazzer.
./jazzer --cp=/home/jackfromeast/Desktop/SkyJenk/tools/jazzer-bin/ --target_class=SimpleFuzzHarness --jvm_args="-agentlib\:jdwp=transport=dt_socket,server=y,suspend=y,address=0.0.0.0\:15005"
The configuration on the client side (IDEAJ).