S.H.E.L.L. CTF 2022 Writeup
- Published on
本次比赛以Th3ee参赛,最终在1092支参赛队伍取得92名的成绩。比赛的题目整体水平比较偏简单(Crypto, Forensic, Misc)。由于比赛没有PWN的题目,所以我本次比赛主要负责Forensics及其他类型的题目。值得一提的是,我们Th3ee的队标新鲜出炉,快点进来看看吧!
We are Th3ee,
We are on the journey to Infinity.

Web
Choosy
XSS漏洞题目,Get请求接受用户输入然后将字符串小写后返回。
首先将Get请求参数替换成最基本的<script>alert(1)</script>,发现回显时script被替换。因此尝试使用img标签避免<script>的js注入,如下所示:
<img src="x" onerror="javascript:alert(1)"/>

此时,response的报文中提供了flag。猜测服务器后端会首先过滤script关键字,然后对选手的输入是否为js代码进行判断。若存在js代码则说明注入成功,服务器后端自动将回显替换为flag。

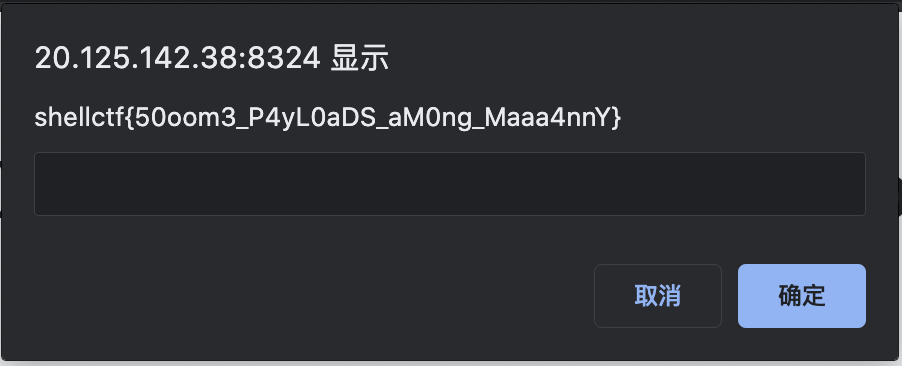
Colour Cookie
简答的变量修题目,关键在于猜测作者用意,并进行尝试。题目要求我们输入一个名称作为 GET 参数name,但并没有回显。

页面回显 flag。

shellctf{C0ooooK13_W17h_c0ooorr3c7_Parr4m37er...}
Reverse Engineering
Pulling the string
反汇编可以发现flag字符串存在的内存地址,寻找到之后。直接提交答案即可


keygen
反汇编之后,寻找到getString函数。在函数当中发现了flag

warmup
反编译之后,发现字符串对比相关函数。
if ( strlen(s) == 27 )
{
v6[0] = 460;
v6[1] = 416;
v6[2] = 404;
v6[3] = 432;
v6[4] = 432;
v6[5] = 396;
v6[6] = 464;
v6[7] = 408;
v6[8] = 492;
v6[9] = 392;
v6[10] = 196;
v6[11] = 464;
v6[12] = 348;
v6[13] = 420;
v6[14] = 212;
v6[15] = 404;
v6[16] = 380;
v6[17] = 192;
v6[18] = 448;
v6[19] = 204;
v6[20] = 456;
v6[21] = 260;
v6[22] = 464;
v6[23] = 192;
v6[24] = 456;
v6[25] = 332;
v6[26] = 500;
v4 = 1;
for ( i = 0; i <= 26; ++i )
v4 = (v6[i] >> 2 == s[i]) & (unsigned __int8)v4;
if ( v4 == 1 )
puts("yes, that's it");
else
puts("nah that's not it");
通过观察函数可以发现,字符串长度必须是27。而且要与v6中每个数值右移4位相同。这样才能保证v4通过 按位与 的操作之后始终保持数值为1。所以呢,我们只需要把v6中的值,一个一个的计算出来就行了。

how to defeat a dragon
反编译之后,flag就在v5里面。是以十六进制的形式表示出来的。


tea
反编译之后,依旧是可以得到flag的长度。但是相较于上面几道,难度增加了一些。
主题逻辑为,通过addSugar、addTea、addMilk等函数,对pwd变量当中存储的输入,进行加密。然后最后通过strainAndServe函数对加密之后的字符串进行判断。

提醒一下,pwd变量是存放在bss段中的public变量。所以其他函数可以直接访问并且进行修改。

我们一个一个来看,首先是addSugar。
for ( i = 0; i < strlen(pwd); ++i )
{
if ( (i & 1) != 0 )
strncat(v2, &pwd[i], 1uLL);
else
strncat(dest, &pwd[i], 1uLL);
}
strncat(v2, dest, 0x11uLL);
strcpy(pwd, v2);
这个 & 按位与 的操作,他是把两个整数以二进制的形式进行操作的。所以 i&1 只有两种结果 1 0。 当i&1=1时,说明 i 的二进制表示最后一位为1 也就是 i 为奇数。 同理,i & 1=0 时,说明 i 为偶数。
那么我们也不难看出,本函数时把 pwd 变为了 奇数位字符串 + 偶数位字符串。
然后看 addTea()。
for ( i = 0; ; ++i )
{
v0 = i;
if ( v0 >= strlen(pwd) >> 1 )
break;
src = pwd[i] + 3 * (i / -2);
strncat(dest, &src, 1uLL);
}
for ( j = strlen(pwd) >> 1; ; ++j )
{
v1 = j;
if ( v1 >= strlen(pwd) )
break;
src = pwd[j] + j / 6;
strncat(dest, &src, 1uLL);
}
strcpy(pwd, dest);
即简单的把pwd分为了两部分,前半部分和后半部分分别采用了不同的线性变化策略。
接着来看addMilk()。
while ( pwd[v3] != "5" && v3 < strlen(pwd) )
strncat(dest, &pwd[v3++], 1uLL);
while ( pwd[v3] != "R" && v3 < strlen(pwd) )
strncat(s, &pwd[v3++], 1uLL);
while ( v3 < strlen(pwd) )
strncat(v14, &pwd[v3++], 1uLL);
v0 = strlen(dest);
strncat(v14, dest, v0);
v1 = strlen(s);
strncat(v14, s, v1);
strcpy(pwd, v14);
不难分析出,此函数将pwd 按照 字符 5 和字符 R 的位置 分别切分为了dest \("5") s \(R) v14 这三个部分。 最后又将这三个部分 按照v14 + dest + s 的方式重新拼接到了一起。
最后我们来看,strainAndServe() 这个函数。
if ( !strcmp("R;crc75ihl`cNYe`]m%50gYhugow~34i", pwd) )
result = puts("yep, that's right");
else
result = puts("nope, that's not it");
return result;
一个简单的字符串比较。
分析完程序的逻辑,我们有了一个大概的思路。即通过最终的字符串,按照逆向的思路一步一步的解析到最初的pwd。
此题关键的地方在于第一步,也就是如何通过"R;crc75ihlcNYe]m%50gYhugow~34i" 得到 v14 、dest 和 s。 我也刚好是栽到了这里。通过之前的分析,我们也可以知道 v14 刚好是以 R开头的。而 dest 中不会含有5这个字符。 s 是以5开头的。
基于我们的分析,s = 50gYhugow~34i可以确定。但 v14 的长度是不确定的。可以是R;crc75,也可以是R;crc75i,也可以是R;crc75ihl`c。所以,dest的长度就是不确定的了。那么产生出来的pwd 也就是不同的。 而我只考虑了 v14 = R;crc75 的情况,解出来的pwd 不符合shellctf的格式。
解密函数如下,值得注意的是,int(3 * (i / 2)) 和 (3 \* int(i / 2)) 在 python里面得到的结果是不一样的。 譬如 i = 3 的时候, 前者的结果为 4 ; 后者的结果为 3 。**这一点需要根据实际情况来进行判断。
s_0 = "R;crc75ihl`cNYe`]m%50gYhugow~34i"
for j in range(6,18):
v14 = s_0[0:j+1]
dest = s_0[j+1:19]
s_1 = s_0[19:]
s = dest+s_1+v14
print(s)
target=[]
for i in range(len(s)):
if i< len(s)/2:
# target.append(chr(ord(s[i]) + int(3 * (i / 2)))) 注意这样写和下面这样写的区别
target.append(chr(ord(s[i]) + (3 * int(i / 2))))
else:
target.append(chr(ord(s[i]) - int(i / 6)))
test = "".join(target)
#print(test)
target2=[]
for i in range(16):
target2.append(target[i+16])
target2.append(target[i])
test = "".join(target2)
print(test)
最终得到符合格式的flag.

one
这个题真的是最坑的一个,主要问题在于,ida反编译出来的代码,于实际的执行情况不符。导致我费了很长时间去理解。为了方便理解,我把整个加密过程切分为一个个的小部分来理解。
首先是第一个, 下面部分把 输入的字符串s 的二进制表示 以字符的形式存储下来。 注意此时是大端存储!(即高位字节位于大的存储地址)
for ( i = 0; i < strlen(s); ++i )
{
for ( j = s[i]; j > 0; j /= 2 )
s[bit_length++ + 48] = j % 2 + 48;
while ( (bit_length & 7) != 0 )
s[bit_length++ + 48] = 48;
}
s[bit_length + 48] = 0;

接着是第二个,以上一步算出来的二进制字符串为基础,每次循环取不同长度once_bit_length(2->3->0->1)的字符,并将通过字符串比较的方式,转换新字符(a-b \c-f \ 1-8 \ 9),存储于v22。
once_bit_length 是从2 开始的。 onece_bit_length = (onece_bit_length + 1) % 4; 刚好 是 2-3-0-1的循环。
当once_bit_length = 2 时,v22中对应的字符为 c - e
当 once_bit_length = 3时, v22中对应的字符为 1- 8
当 once_bit_length = 0 时, v22中对应的字符为 9
当 once_bit_length = 1 时,v22中对应的字符为 a-b。
就这样一直循环,直到取完所有的二进制字符串。(在第一步中求出来的)。 通过观察,我们也可以看出来, v22的规律, 就是 (字母+数字) +( 9+字母) 这样的循环,方便我们后续的解密操作。
这里依旧有个需要注意的地方,我们每次循环只能取 6个字符,但是第一步求出来的二进制字符串是8的倍数,因为一个char类型刚好对应于8 bit, 解出来的字符串就刚好是 8 个 01这样的字符串。 不过,我们不用担心,因为这样的误差最多影响最后一个字符。而通过flag的格式我们已经知道最后一个字符就是 }
while ( v9 < bit_length )
{
*(_QWORD *)s1 = 0LL;
v20 = 0;
v10 = 0;
for ( k = 0; k < onece_bit_length && bit_length > v9 + k; ++k )
{
s1[k] = s[v9 + 48 + k];
++v10;
}
switch ( v10 )
{
case 1:
if ( !strcmp(s1, "0") )
{
*((_BYTE *)v22 + v8) = 97; // a
}
else if ( !strcmp(s1, "1") )
{
*((_BYTE *)v22 + v8) = 98; // b
}
break;
case 2:
if ( !strcmp(s1, "00") )
{
*((_BYTE *)v22 + v8) = 99; // c
}
else if ( !strcmp(s1, "01") )
{
*((_BYTE *)v22 + v8) = 100; // d
}
else if ( !strcmp(s1, "10") )
{
*((_BYTE *)v22 + v8) = 101; // e
}
else if ( !strcmp(s1, "11") )
{
*((_BYTE *)v22 + v8) = 102; // f
}
break;
case 3:
if ( !strcmp(s1, "000") )
{
*((_BYTE *)v22 + v8) = 49; // 1
}
else if ( !strcmp(s1, "001") )
{
*((_BYTE *)v22 + v8) = 50; // 2
}
else if ( !strcmp(s1, "010") ) // 3
{
*((_BYTE *)v22 + v8) = 51;
}
else if ( !strcmp(s1, "011") ) // 4
{
*((_BYTE *)v22 + v8) = 52;
}
else if ( !strcmp(s1, "100") ) // 5
{
*((_BYTE *)v22 + v8) = 53;
}
else if ( !strcmp(s1, "101") ) // 6
{
*((_BYTE *)v22 + v8) = 54;
}
else if ( !strcmp(s1, "110") ) // 7
{
*((_BYTE *)v22 + v8) = 55;
}
else if ( !strcmp(s1, "111") ) // 8
{
*((_BYTE *)v22 + v8) = 56;
}
break;
default:
*((_BYTE *)v22 + v8) = 57; // 9
break;
}
v9 += v10;
++v8;
onece_bit_length = (onece_bit_length + 1) % 4;
}
接下来是第三个,以第二步得到的v22字符串为基础,每两个v22中的字符 决定 一个 v18中的字符。注意观察,实际上v15字符 8bit 中,前4bit 刚好是 (char*)(v22+l) - "a" 或者 (char*)(v22+l) - "0"。后4bit 刚好是 (char*)(v22+l+1) - "a" 或者 (char*)(v22+l+1) - "0"
这样的话,我们就可以通过v15字符中的 8bit 逆向推出 v22 中蕴含的字符。
for ( l = 0; l < v8; l += 2 )
{
if ( *((char *)v22 + l + 1) <= 47 || *((char *)v22 + l + 1) > 57 )// a-f
v14 = *((char *)v22 + l + 1) - 97; // a
else
v14 = *((char *)v22 + l + 1) - 48; // 0
if ( *((char *)v22 + l) <= 47 || *((char *)v22 + l) > 57 )// a-f
v15 = 16 * (*((char *)v22 + l) - 97) + v14;
else
v15 = 16 * (*((char *)v22 + l) - 48) + v14;
v18[v12++ + 96] = v15;
}
最后,对字符串进行比较。
qmemcpy(v18, "R", 0x174uLL);
v16 = 0;
for ( m = 0; m <= 92; ++m )
{
if ( v18[m] == v18[m + 96] )
++v16;
}
就是 qmemcpy(v18, "R", 0x174uLL); 这一句程序困扰了我很长时间,因为按照字面理解 "R" 字符串就只有一个R, 为什么后面的size 参数却有 0x174 这么大呢。原来,在程序的实际执行过程中, "R" 这个位置的参数,只是字符串的首地址。后面还有其他的字符呢。

了解了以上的过程,我们的思路明晰了。还是根据最后的这些字符,一步一步的逆向解析。为了方便起见,我把这些部分字符保存为了二进制文件,因为一个一个的打实在是太费劲了!
import struct
R = []
b = bytes(1) # 0x 00 字节
front_4_base = 240
behind_4_base = 15
fopen = open(r"F:\大四下\CTF\SHEELCTF\test",'rb')
while True:
a = fopen.read(1)
if a == b: # 不要0x00字节,我们只要最前面的 1个字节。
continue
if not a:
break
R.append(struct.unpack('>B', a)[0])
count = 0
target_1=[]
for i in R:
front_4 = (i & front_4_base)>>4
behind_4 = (i & behind_4_base)
if count&1 == 0: # 字母 数字
str_0 = chr(ord("a") + front_4)
str_1 = chr(ord("0") + behind_4)
else: # 数字 字母
str_0 = chr(ord("0") + front_4) # 直接把9加进去
str_1 = chr(ord("a") + behind_4)
count += 1
target_1.append(str_0)
target_1.append(str_1)
print(target_1)
trans_dict = {
"a":"0",
"b":"1",
"c":"00",
"d":"01",
"e":"10",
"f":"11",
"1":"000",
"2":"001",
"3":"010",
"4":"011",
"5":"100",
"6":"101",
"7":"110",
"8":"111",
"9":"",
}
target_2=[]
for i in target_1:
str_2 = trans_dict.get(i)
target_2.append(str_2)
print(target_2)
target_3 ="".join(target_2)
print(target_3)
target_4 = []
target_6 = []
import re
target_4 = re.findall(r'\w{8}', target_3)
for i in target_4:
bit_one = target_6.append(''.join(reversed(i)))
print(target_6)
target_5 = " ".join(target_6)
print(target_5)
def decode(s):
return ''.join([chr(i) for i in [int(b, 2) for b in s.split(' ')]])
print(decode(target_5))
得到最终flag。

Forensics
Alien Communication
查看音频的频谱图即可。

shell{y0u_g07_7h3_f1ag}
Secret Document
题目提示:"shell is the key if you did'nt get it xorry"。
我们可以关注到提示中的"xor"指明了文件是被xor加密过的,key是password(这一个提示思考了很久都没有理解到)。所以我们对文件进行了XOR解密,解密后得到PNG图片。
import os
import binascii
from itertools import cycle
encodedFile = open("/home/kali/Desktop/Shell/secretDocument/Secret-Document.dat","rb").read()
key = 'shell'
decryptedFile = b''
count = 0
for nowByte in encodedFile: # 通过迭代器逐字符处理
newByte = nowByte ^ ord(key[count % len(key)])
count += 1
decryptedFile += bytes([newByte])
with open('decodedFile.png', 'wb') as png:
png.write(decryptedFile)

Heaven
题目提示:"I was in the seventh heaven painted red green and blue"。

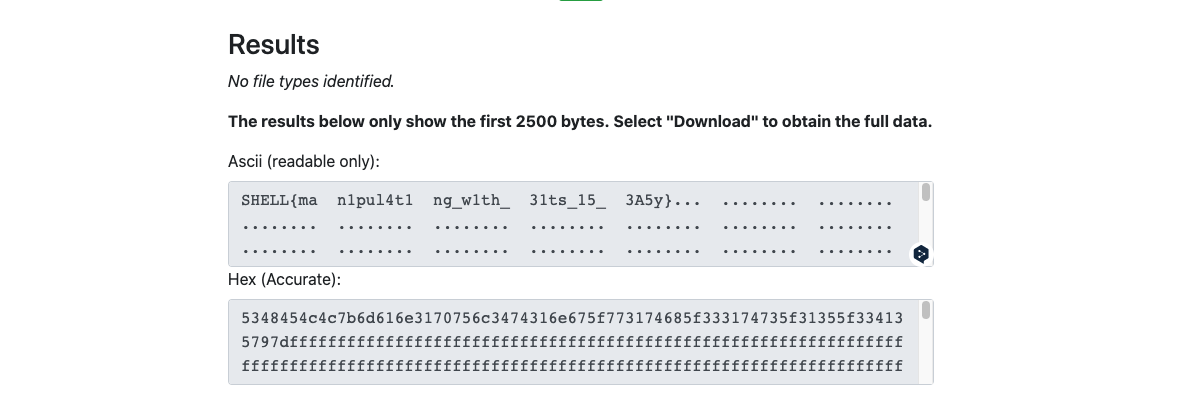
Hidden File
查看本题目中给出的jpg文件,其中给出了一个密码为shell。因此,jpg是采用了某种需要使用密码加密的算法,比如stegohide, OpenStego, Stegpy, Outguess, Jphide等。

使用stegohide解密果然存在加密的文件夹。

所给的文件夹含有三个文件:flag.zip, se3cretf1l3.pdf,something.jpg. 第一个zip显然被加密过,第三个jpg中的二维码为钓鱼链接,是YouTube的一个视频。因此,密码存在第二个文件pdf中。

分析PDF文件,一开始想从梳理PDFObject来做,网上有很多现成的软件,比如(Polyfile)[https://github.com/trailofbits/polyfile],可以生成html可互动的pdf分析,如下所示。但是很遗憾并没有找到有用的信息。

之后,在网上找到了提取PDF的工具,提取后发现了zip的解密密码。


Go Deep!
Our one of the agent gave us this file and said "Go Deep!"
同样,本题目中所给出的音频从hex中可以得到一个密码。猜想是采用了某种需要密码的音频加密方法,再加上题目提示中的Go Deep,所以直接使用DeepSound来进行解密。


文件中存在 flag.
SHELL{y0u_w3r3_7h1nk1ng_R3ally_D33p}
Cryptography
Typing Typing
题目中给出的密码如下所示。显然是莫斯密码,但是却有非常规律的特征,比如使用/分割的一段中拥有同样的符号组合,符号均为5位等。直接用摩斯密码解密后得到一串数字。
----. ----. ----. / -.... -.... -.... / ---.. ---.. / ..--- ..--- ..--- / ..--- / -.... -.... / --... --... --... / ...-- ...-- / ..--- / ...-- / -.... / ----. ----. ----. / --... --... --... --... / -.... / --... --... --... --...

对着密码思考许久之后,结合题目背景(Typing and SMS),猜想会不会与手机按键有关。果然解密得到答案。

MALBORNE
该题目没有任何的技巧性,关键在于认识该语言。[MALBORNE][https://zh.m.wikipedia.org/zh-hans/Malbolge]
因此我们只需对该语言进行编译运行即可,[在线平台][https://malbolge.doleczek.pl/]。执行效果如下,得到 flag。

SHELL{m41b01g3_15_my_n3w_l4ngu4g3}
OX9OR2
题目为经典异或加密题目。题目提供了两个文件,一个加密后的密文,一个是加密过程代码文件。
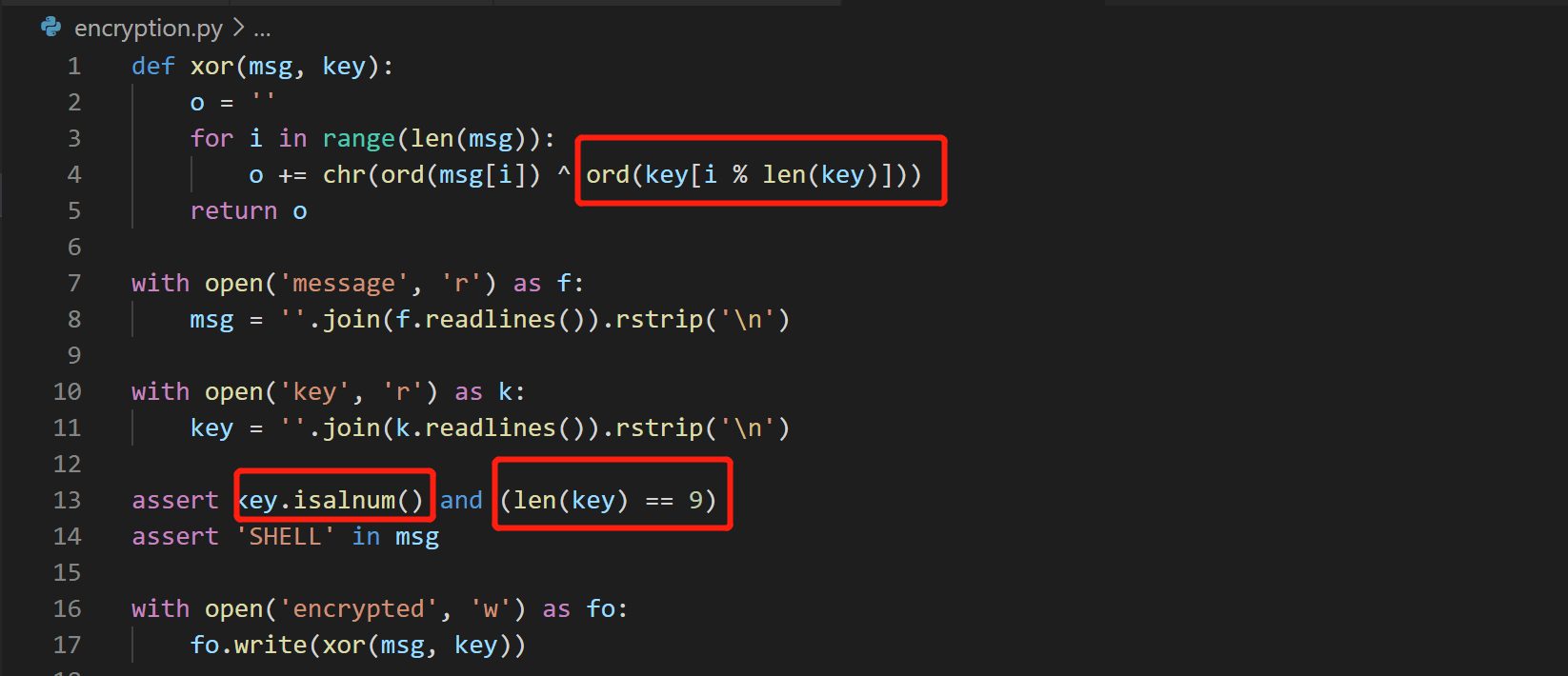
根据代码可知四个关键点,(1)key均为字母;(2)key共有9个字母;(3)加密时模9,即循环使用key异或;(4)知道 FLAG 格式为SHELL{}。因此可以根据这些来破解,首先根据 SHELL{ 获得 key的前 6 个字符为 XORISC,进而对后面三个字母进行爆破。遍历字母表,在经过查看之后,发现当 key = XORISCOOL 时,FLAG 具有较好的可读性,便获得了 flag。

SHELL{X0R_1S_R3VeR51BL3}
Feel Me
该题目为视频处理 + 常规解密题目。题目提供了一个 MP4 文件,内容为 3 * 2 的六位数字(均为0,1)的快速变化。
我们首先需要将视频进行慢放,这里我使用了 [PotPlayer-win][https://potplayer.daum.net/] 对视频进行逐帧查看,并获得了如下序列。

结合题目名称,猜测为盲文解密,但是查看后发现盲文为 8 位数字,便放弃了,后面感觉还是盲文解密,查询后发现 8 位为拓展后的,原始版本为6位,解密后获得 SHEL YOUCANSEME SHEL,近在咫尺,并进行了一定的猜测,由于SE和SEE在查看变化是可能无法辨别E十分发生重复,但是为了使 FLAG 更加有寓意,便将其转为SEE,最终猜测出 Flag。
SHELL{YOUCANSEEME}
Miscellaneous
World's Greatest Detective
改题目需要搜索对应的符号。题目提供了包含一串奇怪的符号的图片。
经查询为电影黑豹中的语言,接着进行对应的翻译即可。
SHELLCTF{W4kandA_F0rev3r}