本文对共指消解任务的常见评价指标MUC、B-Cubed、CEAF和LEA的算法思想、具体计算方法和示例进行阐述。
共指关系是一种等价关系,具有共指关系的实体属于同 一个等价类。共指消解就是将文本中所有名词短语组成的全集划分为一系列互不相交 的等价类子集的过程。评价之前需要有标准答案的划分(Key),待评价系统的输出划分 (Response)。评价过程就是比较两个划分:Key 和 Response。
相比于分类问题,评价Key和Response这两个集合划分的近似程度比较复杂,所以近年来有多种评价指标的出现包括MUC,B-Cubed,CEAF,BLANC,LEA等。但是我并没有找到详细讲述每种评价指标的思想和具体细节的文章,所以我在此对其中的关键评价指标进行比较详细的解析。
目前首先对MUC、B-Cubed、CEAF和LEA这四种评价指标进行解析,之后有时间会继续更新BLANC。此外需要说明的是,评价指标的好坏没有量化的依据,只是从更多例子我们可以看到不同评价指标表现,从而发现评价指标的缺点。一个共指消解模型能在多个评价指标下均保持比较高的得分可以说明它的能力是稳定的,不会倾向于生成更多共指簇或者通过其他行为来提高某评价指标上的表现。
1 MUC
Vilain, M., J. D. Burger, J. Aberdeen, D. Connolly, and L. Hirschman. 1995. A model-theoretic coreference scoring scheme. MUC-6.
1.1 MUC 评价指标引入
Vilain et al. 讲共指簇的划分从完全图和对应的生成树来考虑。如下图所示,表述对的共指关系可以生成共指簇;而共指簇对应着一个等价完全图,表述对的共指关系就对应着图中的边。其中,由表述对共指关系所生成的边对应着该完全图的一个连通子图。
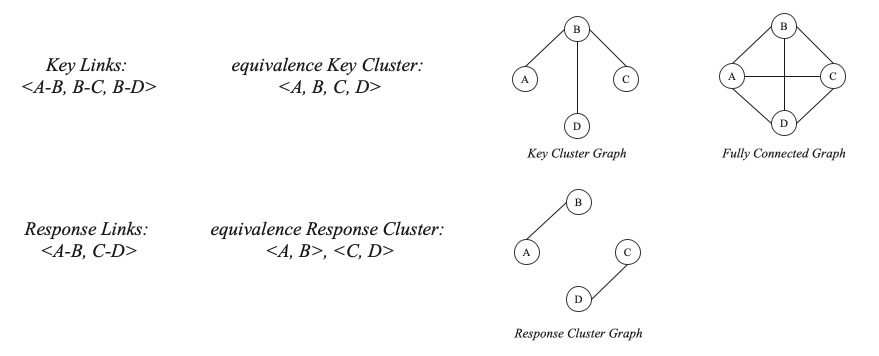
直观地来看(From the intuitive notion),精度代表着所有预测的边中正确预测的比例,由于Response的边A-B和C-D均在Key等价完全图中,所以其计算应该是2/2=1;召回率的计算代表着正确的边中被正确预测的比例,由于形成Key等价完全图至少需要3条边,所以其计算应该是2/3=0.677。对于召回率的计算,从图的角度来看,Response Cluster Graph仍最少需要添加一条边来得到Key等价完全图的最小连通子图(生成树),也就是说Response Cluster Graph完成了Key等价完全图的最小连通子图的2/3。Key等价完全图的最小连通子图对应着Key Cluster,而Response Cluster Graph对应着Response Cluster,所以两cluster的比较可以比较直接地从图的表示上来计算。
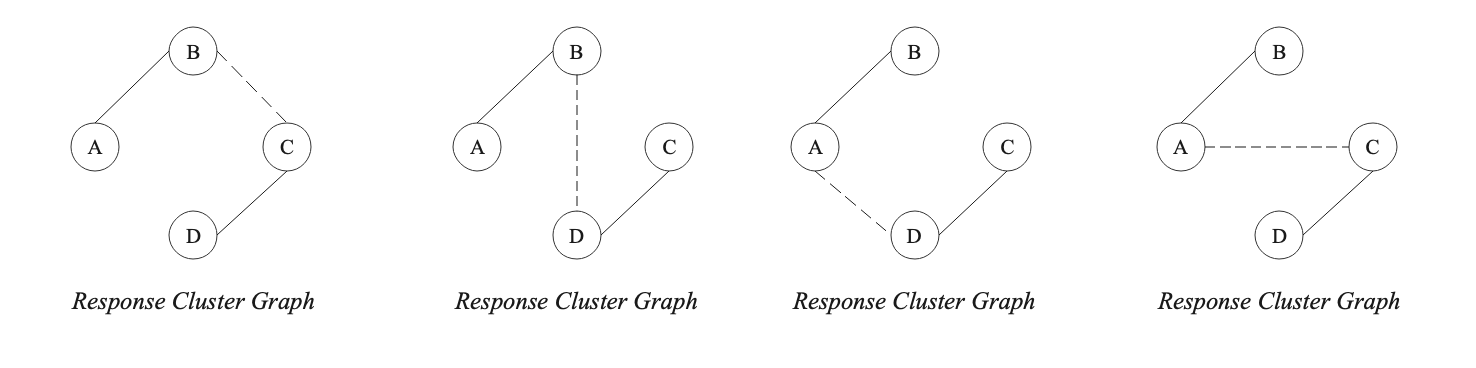
由下图可见,Response Cluster图添加以下任意一条虚线都可以生成Key Cluster的最小连通子图,也就是生成标注的黄金共指簇。
接下来从数学的角度定义精度和召回率的计算。
1.2 MUC 召回率计算
首先,令
为 与每个 集合取所有在S集合中的元素所生成的新集合。因为召回率的基本定义,我们需要去除 中所有不在此S集合的元素。此外需要注意的是, 中仍包含单共指簇(singleton)。举例来看, 则 ; 为生成该黄金共指簇所需要的最小边数; m(S)为由R生成S仍需添加的最小边数量,如1.1中,Response Cluster所需添加的边数就为1;
综合以上,可以得到MUC的召回率为:
1.3 MUC 精度计算
精度的计算的对象转换成了Response Clusters,其余其实与MUC的召回率计算类似。
首先,对于Response Clusters中一预测共指簇由
为 与每个 集合取所有在 集合中的元素所生成的新集合。因为精度的基本定义,我们需要去除 中所有不在此 集合的元素。此外需要注意的是, 中仍包含单共指簇(singleton)。举例来看, 则 ; 为生成该 所需要的最小边数; 为由 生成S'仍需添加的最小边数量,其实也对应着 被错误预测的边数;
综合以上,我们可以得到MUC精度的计算如下:
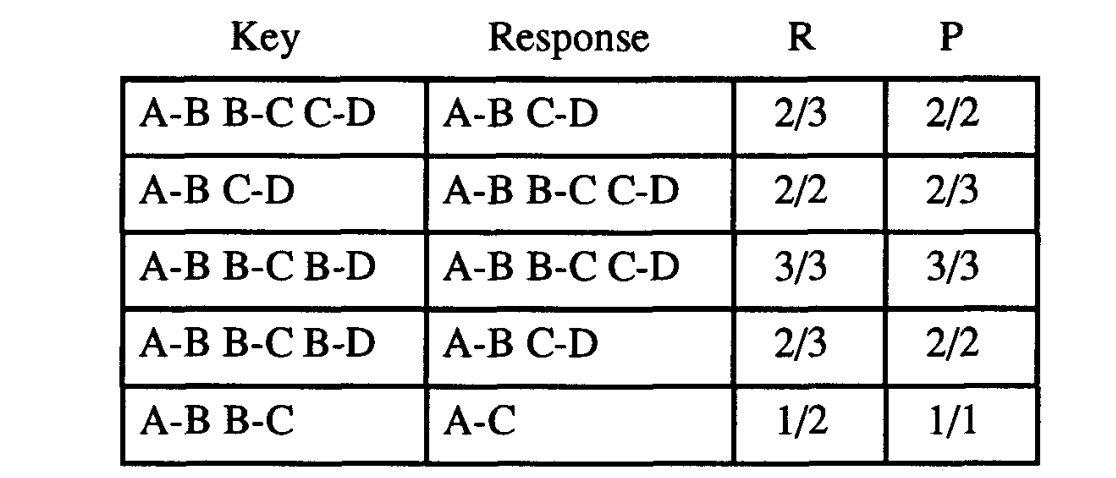
1.4 示例
这里放一下原论文中所给出的计算示例,有兴趣的朋友可以手动计算并且核对一下。
1.5 MUC 评价分析
我们知道,共指消解模型会对三种候选表述进行划分:实际非表述,无共指关系的表述和有共指关系的表述。优秀的消解模型会有共指关系的候选正确归类,同时虽然对实际非表述和无共指关系的表述都不进行分类,但在候选表述挑选时尽量将实际非表述的数量控制在最低水平。
但是MUC对于未分类的候选表述的认识是错误,均默认为无共指关系的正确表述,生成单共指簇。
以计算精度为例,MUC在计算p'(S')时将没有出现在黄金共指簇中的预测的表述默认当作被手动标注为单共指簇的表述。但实际情况下,可能是消解模型错误预测的候选表述。
以召回率计算为例,MUC在计算p(S)时将没有出现在所预测共指簇中的黄金表述默认当作该消解模型预测的单共指簇。但实际情况下,消解模型可能都没有正确提取该表述。
E.g. Key=[{A, B, C}], Response=[{B, C}],此时计算得到的p(S) = [{B,C}, {A}],但是实际上消解模型可能都不知道A表述的存在。
被正确预测的单共指簇对于MUC评价指标没有任何影响。
E.g. Key=[{A, B, C}, {D}], Response=[{B, C}, {D}]与上述情况下的结果一模一样,但是2.中的消解模型的能力显然比1.的更好。
2 B-Cubed
Bagga, A. and B. Baldwin. 1998. Algorithms for scoring coreference chains. LREC Workshop on Linguistic Coreference.
2.1 B-Cubed 评价指标引入
B-Cubed算法的提出是基于MUC-6算法的如下两个问题:
MUC-6算法并没有考虑到单共指簇,因为MUC中是根据簇对应图的缺失边来计算的,而单共指簇没有边,也就是说被正确划分的无共指表述被MUC所忽略了;
MUC-6中所有错误都被同等看待,但是显然有一些错误对正确类的划分影响更大。B-Cubed算法的作者举例来进行说明。
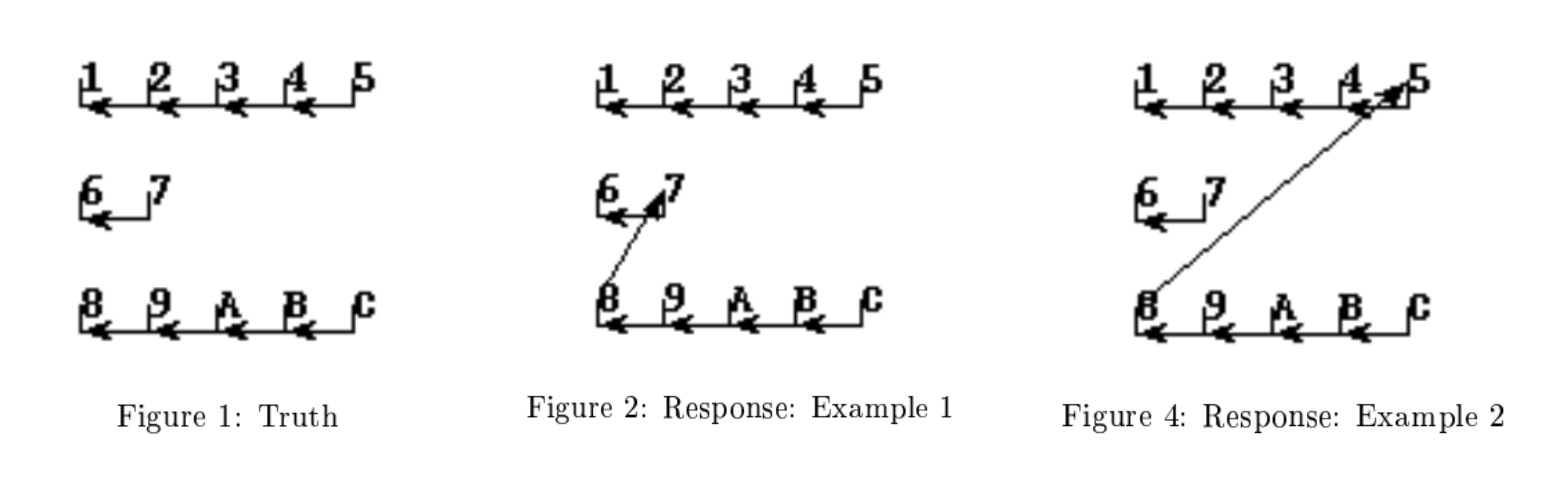
作者提出Figure4中的Response划分相比于Figure2,对整个系统的划分影响更大,但是MUC-6算法却为两个Response给予相同的精度0.9.
综合以上两个问题,作者基于MUC算法提出B-Cubed算法来解决以上两个问题。
最终得到Precison和Recall的计算如下:
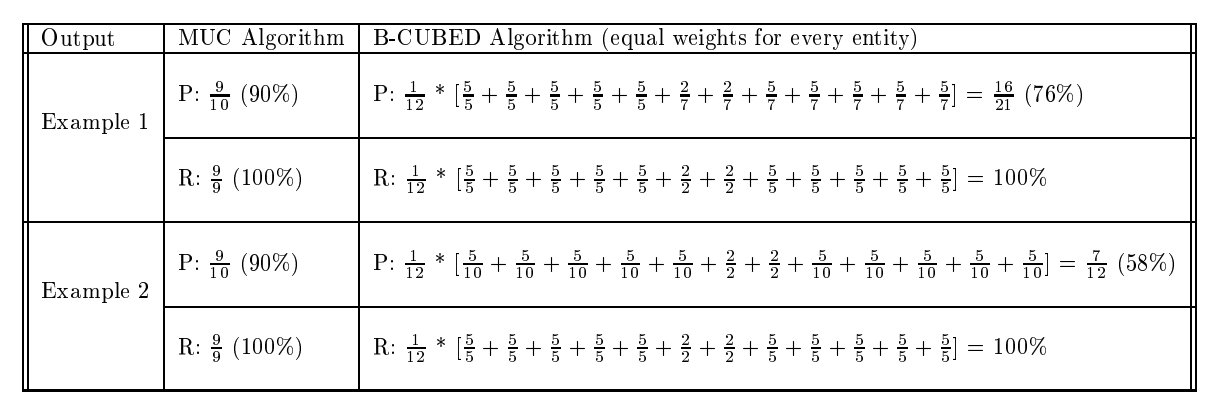
为什么说B-Cubed可以解决MUC所带来的问题呢?
首先,由于B-Cubed计算所有黄金共指簇中的Mention,所以也包括单共指簇,这也就解决MUC的第一个问题。其次,根据共指关系的传递性,我们可以得到无论是Response还是Key中,任意一个Mention只可能存在于一个共指簇中。所以,以B-Cubed的方式我们可以得到被划分错误的mention对于整个划分的影响。比如上述例子中,Example1中的Mention6,计算得到的Precision_6=2/7, Example2中的MentionA,计算得到的Precision_A=5/10.
2.2 B-Cubed 召回率计算
首先,令
为 与每个 集合取所有在S集合中的元素所生成的新集合。因为召回率的基本定义,我们需要去除 中所有不在此S集合的元素。 ,其中 均为S的子集; 为 中集合 相比于 所缺少的元素的数量;
接着我们得到,
2.3 B-Cubed 精度计算
B-Cubed精度的计算与召回率类似,可以参照MUC的精度计算和MUC召回率计算进行类比。
3 CEAF
Xiaoqiang Luo. 2005. On Coreference Resolution Performance Metrics. In Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, pages 25–32, Vancouver, British Columbia, Canada. Association for Computational Linguistics.
Luo等人对评价指标给出了一般性的评判准则:1. 良好的分辨性,即一个好的共指消解模型在得分上应该比一个坏的共指消解模型评分高;2.可解释性,当指标给出一个很高的分数时,我们可以推断该模型将大部分候选表述都已正确地划分;因此,作者分析了MUC和B-Cubed评价指标的问题,并且提出了Constrained Entity-Alignment F-Measure评价指标。其中mention-based CEAF反应了候选表述被正确划分到实体的比例,entity-based CEAF反应着被正确识别(划分)的实体。
CEAF算法相比于之前的算法更加直观的表现了我们评价共指簇划分的好坏,就是对应地比较每个共指簇划分。但是如何最优地对应Response和Key的共指簇有一定难度,所以CEAF算法在计算上更加复杂。接下来,将详细介绍下CEAF评价指标的计算。
3.1 CEAF 评价指标计算
对于文档
由于接下来我们需要将
由此,我们可以提取出
接着,我们继续为比较不同映射
其中
所以,对于任何一种映射
至于如何寻找到最佳映射
因此,作者将共指簇对齐问题建模为经典的二分图最大匹配问题。每一个共指簇为二分图中的一个顶点,而共指簇对所计算的相似度就成为边的权重。该问题通过Kuhn-Munkres 算法可以在多项式时间中被解决。
4 LEA
Moosavi N S, Strube M. Which coreference evaluation metric do you trust? a proposal for a link-based entity aware metric[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016: 632-642.
LEA(Link-based Entity-Aware)评价指标将综合考虑实体的重要性以及其被消解的情况。LEA在评价共指划分时将遵循以下公式作为其指导思想:
考察实体共指预测情况的函数